.. index:: pair: page; Tutorials
:target:`tuts__tutorials_1md_openvino_docs_tutorials`
.. toctree:: :maxdepth: 2 :caption: Notebooks :hidden: :glob: notebooks-installation notebooks/*
This collection of Python tutorials are written for running on Jupyter notebooks. The tutorials provide an introduction to the OpenVINO™ toolkit and explain how to use the Python API and tools for optimized deep learning inference. You can run the code one section at a time to see how to integrate your application with OpenVINO libraries.
Notebooks with a
button can be run without installing anything.
Once you have found the tutorial of your interest, just click the button next to
the name of it and Binder will start it in a new tab of a browser.
Binder is a free online service with limited resources (for more information about it,
see the Additional Resources section).
Note
For the best performance, more control and resources, you should run the notebooks locally. Follow the Installation Guide in order to get information on how to run and manage the notebooks on your machine.
Contents:
The Jupyter notebooks are categorized into four classes, select one related to your needs or give them all a try. Good Luck!
Brief tutorials that demonstrate how to use Python API for inference in OpenVINO.
| Notebook | Description | Preview |
|---|---|---|
| 001-hello-world |
Classify an image with OpenVINO. |  |
| 002-openvino-api |
Learn the OpenVINO Python API. |  |
| 003-hello-segmentation |
Semantic segmentation with OpenVINO. |  |
| 004-hello-detection |
Text detection with OpenVINO. |  |
Tutorials that explain how to optimize and quantize models with OpenVINO tools.
| Notebook | Description | Preview |
|---|---|---|
| 101-tensorflow-to-openvino |
Convert TensorFlow models to OpenVINO IR. |  |
| 102-pytorch-onnx-to-openvino | Convert PyTorch models to OpenVINO IR. |  |
| 103-paddle-onnx-to-openvino |
Convert PaddlePaddle models to OpenVINO IR. |  |
| 104-model-tools |
Download, convert and benchmark models from Open Model Zoo. |  |
.. dropdown:: Explore more notebooks here. +------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------+ | Notebook | Description | +==============================================================================================================================+==================================================================================================================================+ | `105-language-quantize-bert <notebooks/105-language-quantize-bert-with-output.html>`__ | Optimize and quantize a pre-trained BERT model | +------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------+ | `106-auto-device <notebooks/106-auto-device-with-output.html>`__ | Demonstrates how to use AUTO Device | +------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------+ | `107-speech-recognition-quantization <notebooks/107-speech-recognition-quantization-with-output.html>`__ | Optimize and quantize a pre-trained Wav2Vec2 speech model | +------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------+ | `110-ct-segmentation-quantize <notebooks/110-ct-segmentation-quantize-with-output.html>`__ | Quantize a kidney segmentation model and show live inference | +------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------+ | `111-detection-quantization <notebooks/111-detection-quantization-with-output.html>`__ |br| |n111| | Quantize an object detection model | +------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------+ | `112-pytorch-post-training-quantization-nncf <notebooks/112-pytorch-post-training-quantization-nncf-with-output.html>`__ | Use Neural Network Compression Framework (NNCF) to quantize PyTorch model in post-training mode (without model fine-tuning) | +------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------+ | `113-image-classification-quantization <notebooks/113-image-classification-quantization-with-output.html>`__ | Quantize mobilenet image classification | +------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------+ | `114-quantization-simplified-mode <notebooks/114-quantization-simplified-mode-with-output.html>`__ | Quantize Image Classification Models with POT in Simplified Mode | +------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------+ | `115-async-api <notebooks/115-async-api-with-output.html>`__ | Use Asynchronous Execution to Improve Data Pipelining | +------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------+
Demos that demonstrate inference on a particular model.
| Notebook | Description | Preview |
|---|---|---|
| 210-ct-scan-live-inference |
Show live inference on segmentation of CT-scan data. |  |
| 211-speech-to-text |
Run inference on speech-to-text recognition model. |  |
| 208-optical-character-recognition | Annotate text on images using text recognition resnet. |  |
| 209-handwritten-ocr |
OCR for handwritten simplified Chinese and Japanese. |  的人不一了是他有为在责新中任自之我们 |
| 218-vehicle-detection-and-recognition | Use pre-trained models to detect and recognize vehicles and their attributes with OpenVINO. |  |
.. dropdown:: Explore more notebooks below. +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | Notebook | Description | Preview | +===============================================================================================================================+============================================================================================================================================+===========================================+ | `201-vision-monodepth <notebooks/201-vision-monodepth-with-output.html>`__ |br| |n201| | Monocular depth estimation with images and video. | |n201-img1| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `202-vision-superresolution-image <notebooks/202-vision-superresolution-image-with-output.html>`__ |br| |n202i| | Upscale raw images with a super resolution model. | |n202i-img1| → |n202i-img2| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `202-vision-superresolution-video <notebooks/202-vision-superresolution-video-with-output.html>`__ |br| |n202v| | Turn 360p into 1080p video using a super resolution model. | |n202v-img1| → |n202v-img2| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `203-meter-reader <notebooks/203-meter-reader-with-output.html>`__ |br| |n203| | PaddlePaddle pre-trained models to read industrial meter's value | |n203-img1| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `204-named-entity-recognition <notebooks/204-named-entity-recognition-with-output.html>`__ |br| |n204| | Perform named entity recognition on simple text. | |n204-img1| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `205-vision-background-removal <notebooks/205-vision-background-removal-with-output.html>`__ |br| |n205| | Remove and replace the background in an image using salient object detection. | |n205-img1| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `206-vision-paddlegan-anime <notebooks/206-vision-paddlegan-anime-with-output.html>`__ |br| |n206| | Turn an image into anime using a GAN. | |n206-img1| → |n206-img2| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `207-vision-paddlegan-superresolution <notebooks/207-vision-paddlegan-superresolution-with-output.html>`__ |br| |n207| | Upscale small images with superresolution using a PaddleGAN model. | |n207-img1| → |n207-img2| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `212-onnx-style-transfer <notebooks/212-onnx-style-transfer-with-output.html>`__ |br| |n212| | Transform images to five different styles with neural style transfer. | |n212-img1| → |n212-img2| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `214-vision-paddle-classification <notebooks/214-vision-paddle-classification-with-output.html>`__ |br| |n214| | PaddlePaddle Image Classification with OpenVINO. | | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `215-image-inpainting <notebooks/215-image-inpainting-with-output.html>`__ | Fill missing pixels with image in-painting. | |n215-img1| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `216-license-plate-recognition <notebooks/216-license-plate-recognition-with-output.html>`__ | Recognize Chinese license plates in traffic. | |n216-img1| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `217-vision-deblur <notebooks/217-vision-deblur-with-output.html>`__ |br| |n217| | Deblur Images with DeblurGAN-v2. | |n217-img1| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `219-knowledge-graphs-conve <notebooks/219-knowledge-graphs-conve-with-output.html>`__ | Optimize the knowledge graph embeddings model (ConvE) with OpenVINO | | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `220-yolov5-accuracy-check-and-quantization <notebooks/220-yolov5-accuracy-check-and-quantization-with-output.html>`__ | Quantize the Ultralytics YOLOv5 model and check accuracy using the OpenVINO POT API | |n220-img1| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `221-machine-translation <notebooks/221-machine-translation-with-output.html>`__ | Real-time translation from English to German | | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `222-vision-image-colorization <notebooks/222-vision-image-colorization-with-output.html>`__ | Use pre-trained models to colorize black & white images using OpenVINO | |n222-img1| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+ | `223-gpt2-text-prediction <notebooks/223-gpt2-text-prediction-with-output.html>`__ | Use GPT-2 to perform text prediction on an input sequence | |n223-img1| | +-------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------+
Tutorials that include code to train neural networks.
| Notebook | Description | Preview |
|---|---|---|
| 301-tensorflow-training-openvino | Train a flower classification model from TensorFlow, then convert to OpenVINO IR. |  |
| 301-tensorflow-training-openvino-pot | Use Post-training Optimization Tool (POT) to quantize the flowers model. | |
| 302-pytorch-quantization-aware-training | Use Neural Network Compression Framework (NNCF) to quantize PyTorch model. | |
| 305-tensorflow-quantization-aware-training | Use Neural Network Compression Framework (NNCF) to quantize TensorFlow model. |
Live inference demos that run on a webcam or video files.
| Notebook | Description | Preview |
|---|---|---|
| 401-object-detection-webcam |
Object detection with a webcam or video file. | 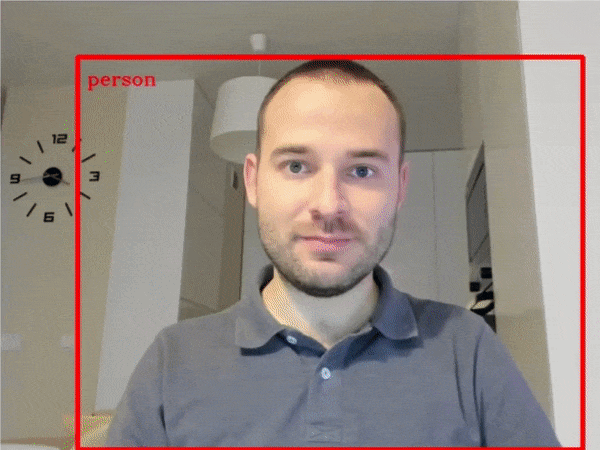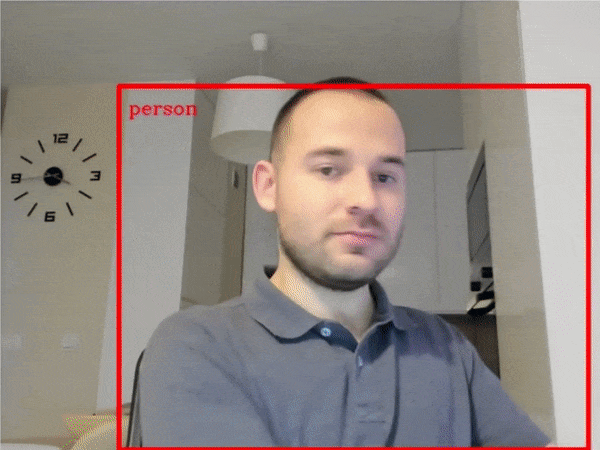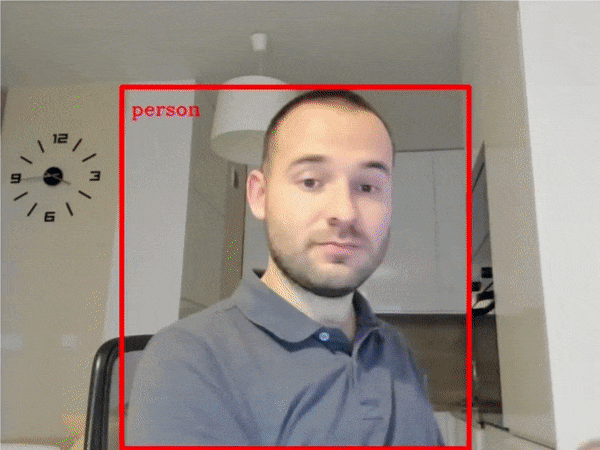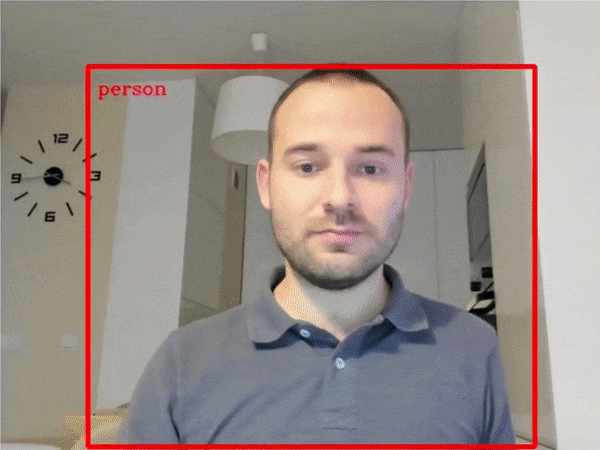 |
| 402-pose-estimation-webcam |
Human pose estimation with a webcam or video file. |  |
| 403-action-recognition-webcam |
Human action recognition with a webcam or video file. |  |
| 405-paddle-ocr-webcam |
OCR with a webcam or video file |  |
The following tutorials are guaranteed to provide a great experience with inference in OpenVINO:
| Notebook | Preview | |
|---|---|---|
| Vision-monodepth |
Monocular depth estimation with images and video. |  |
| CT-scan-live-inference |
Show live inference on segmentation of CT-scan data. | |
| Object-detection-webcam |
Object detection with a webcam or video file. | |
| Pose-estimation-webcam |
Human pose estimation with a webcam or video file. | |
| Action-recognition-webcam |
Human action recognition with a webcam or video file. | |
Note
If there are any issues while running the notebooks, refer to the Troubleshooting and FAQ sections in the Installation Guide or start a GitHub discussion.
Made with contributors-img.