Journal
I decided I'd write a backup program, because I was frustrated with slow or failed restores from Duplicity, and with other open source solutions. I love Rust and thought it'd be good to write a real application in it. Also, I learned things both good and bad about storage formats and performance from bzr, and wanted to try to apply them.
Conserve has been a long time coming, with my earliest notes on an idea for it dating back to 2011 or earlier. It'll be a while longer before it's ready, as it only gets a couple of hours a week, not even every week.
My day job has very large systems with complicated requirements and environments, so it's very refreshing to work on something I entirely understand and where I can decide the requirements myself. I do miss simply writing programs.
I decided to write a journal about development, as a record and to enhance the reflective process.
Finally we have a useful conserve diff, although more could still be added to
it. In particular it reports whether file mtimes/sizes are the same, which is
cheap but only approximately true. We might be interested whether the content
changed even if the mtime is the same, or the opposite.
(https://github.com/sourcefrog/conserve/commit/18ed848e375eb368efb3e0a965152b940d2acccf)
I got annoyed that tests for large files are slow, especially in debug builds. Some of it was due to building a long string for the content of the file. Also, there were two very similar tests for writing large files and we really only need one. (https://github.com/sourcefrog/conserve/commit/e94ef581fac0f5f0fd2e5a9a80a78e32c4d172c5)
Previously I had a WriteTree, CopyTree abstraction, with the idea of
implementing them on both live trees (for restore) and archives (for backup).
However it doesn't seem to fit very well, especially as I tried to make both
operations faster and more parallelized. The performance characteristics of the
two are different enough that an abstraction over them may not perform well, or
at least it will need to be more subtle than I had here. Also, there are only
two implementations, and we don't expect to remix them very much, so perhaps the
abstraction was not really worthwhile.
This also allows removing the overly generic CopyStats: stats and their
presentation to the user are another aspect in which backup and restore are not
really the same.
(https://github.com/sourcefrog/conserve/commit/f25bb9d4f54276473708106a6e2521a5d827ddcb)
Also, after some refactoring to make it threadsafe, I got threaded readahead going in diff, and it should be generally applicable. That's really satisfying Rust. (https://github.com/sourcefrog/conserve/commit/456efe366fc72ac6421b2e6ee40afa99384713a4)
I tried using indicatif to avoid maintaining my own progress-bar code but it has some drawbacks:
-
Can't both draw colored output and progress bars.
-
Can't stop it showing decimal sizes(?) which is noisy.
-
It parses the template using regexps on every update which may not really show up as a problem but seems pretty inefficient.
On the whole I'll reluctantly go back to drawing it myself, but perhaps
carry across some of the ui code refactoring.
My motivation for this was, in part, open bug https://github.com/sourcefrog/conserve/issues/75 about progress currently not working at all on Windows.
Possibly this is better addressed by switching to https://github.com/crossterm-rs/crossterm.
For various reasons there have been long gaps in development. I'd like to do better at picking this up and continuing work after a break, with less resumption latency. Maybe writing here can keep better momentum.
Perhaps the largest blocker to full use for me is backup speed, and I think a big driver of that is repeatedly hashing files that haven't changed since the last backup. I want to use the file mtime/ctime to determine that they haven't changed since the last run.
This requires traversing the last-stored tree and the source tree in parallel.
One prior refactoring to help with this was to rename diff to merge, as
really what it's doing is just joining two tree iterators. Perhaps join
would have been even better.
I'm not sure if this should directly go into copy_tree or if this is too
backup-specific, or would complicate that contract...
I can imagine doing a restore that overwrites an existing tree, or rather merges in to it. In that case we'd want to also look at existing files. But rather than copying them, we'd want to mark it as unchanged from the existing version, which in that case means just doing nothing. So, perhaps there should be a way to tell WriteTree to mark a file as unchanged, passing the file entry...
Should we provide a basis tree, or should that be part of the WriteTree contract?
I had a dream that I needed to give an impromptu talk about Python and I ended up giving a talk about why to use Rust instead. Although I do think there are some areas where Python's a better fit, I probably wouldn't have done something similar to bzr in Python.
So what did I learn, from bzr, and what am I learning here?
Performance matters! The approach of getting the right UI first and then optimizing the implementation, although it sounds nice, doesn't work, or at least I would have had to move on to performance much faster than I did there.
Formats matter! For systems with persistent data, the format can determine performance, and once people have data they care about in that format it can be hard to shift.
Working to support storage of archives on dumb remote filesystems, with good performance, was probably not a smart choice: the feature is sometimes valuable to some people, but not that valuable, and it constrains other work. That said, I still want to support it in Conserve because I think the cases for writing backups directly to cloud storage are pretty strong, and then support for sftp is easy enough to also have.
Struggling in Python against errors that show up only in tests, and only in a test suite that eventually took some time to run, was really no fun. Once you get past a certain (not very large) size, it's so much better to have compile time checking. (Python now has pytypes but that seems pretty weak.)
In particular, unicode handling was a bugbear. Duck typing seems like a very
poor fit for this: in filenames or other input data many of them will be
able to be treated as ascii but some will not, and you have to exercise the
non-latin case the right way to test it. Rust's separation between bytes,
OsStr, and String, seems much cleaner.
For that matter it really dates Python that it's using UCS-2 or UCS-4 internally rather than UTF-8. (It looks like, after https://www.python.org/dev/peps/pep-0393/, Python can choose at runtime which UCS representation to use, but it's never UTF-8, although it can also cache a UTF-8 representation. It's rather complex.)
I love how well things can be parallelize in Conserve with Rayon. For validation it can saturate a 16-thread machine, and I expect to soon get there for the rest of backup and restore.
On today's machines profiling to see where your task is spending time, although of course a good idea, might not be the most important question. One should also ask: where is it leaving other cores idle?
So this is partly about just having a language without a global interpreter lock, that can issue many operations in parallel, but more importantly it's about the fearless concurrency: having confidence that running these operations in parallel will have the correct behavior and not introduce subtle bugs. I think in Python, even with no GIL, that would have been harder.
There's something refreshing, too, about building something that doesn't need to please anyone else or move quickly. Of course it's good if software be useful and address people's needs and be done soon, but it's also good to just craft and hone and contemplate this.
Performance is more predictable.
Cross-platform issues are handled at least equally well.
There are some things in Rust where I can't work out how to make the compiler accept it - some are running into the lack of non-lexical lifetimes or other borrowck restrictions. That didn't exactly happen in Python. Usually there's a way to restate it, sometimes a bit longer than ideal, but sometimes really no worse.
I think Python probably still wins out when you want just a quick sketch of code, and obviously it can directly support a repl. I think Python may always be more accessible to people who don't want, in that context, to think too hard about what the program's doing or its correctness. I'm not sure Python is really any simpler than Rust, but it's more willing to let you take your chances with correctness.
Probably, in bzr, we should have moved much earlier and more aggressively to having a C++/Python hybrid. I was afraid of the build-chain complexity of doing this, but having complicated slow Python was a worse choice. But then, I think I'd rather have everything in one language that can get a good mix of safety, expressiveness, and performance.
Changing to one BlockDir across the whole archive seems like a good and simple improvement, and maybe a really obvious format to use here. Why didn't I use it before? I think because I was worried about the speed and safety of garbage collection from it, but no I think it's feasible.
It's not exactly the same but I think in bzr I made a mistake in making overly pessimistic format assumptions for the sake of supporting direct storage on FTP or SFTP, which in the end is not such an amazing format.
I guess having now asserted that gc will not be so hard, perhaps I ought to implement it to prove that, or do otherwise.
With this change it seems like efficiency is at the point where it can be fairly practically used. I'm not sure incremental indexes are even really needed urgently.
Some likely next steps are:
- gc blocks, at least to be sure it can be done
- more debug commands
- purge, especially old incomplete versions
- diff, especially to check whether there were any changes vs source
- validate/check
- show archive sizes
- maybe change to more concise msgpack indexes -- not very urgent but would keep the format stable
I tried using macOS Instruments to profile Conserve, especially because backups
seem a bit slower than I would expect, and the time shown in --stats doesn't
add up to the apparent total run time.
Here are some decent instructions from carols10cents
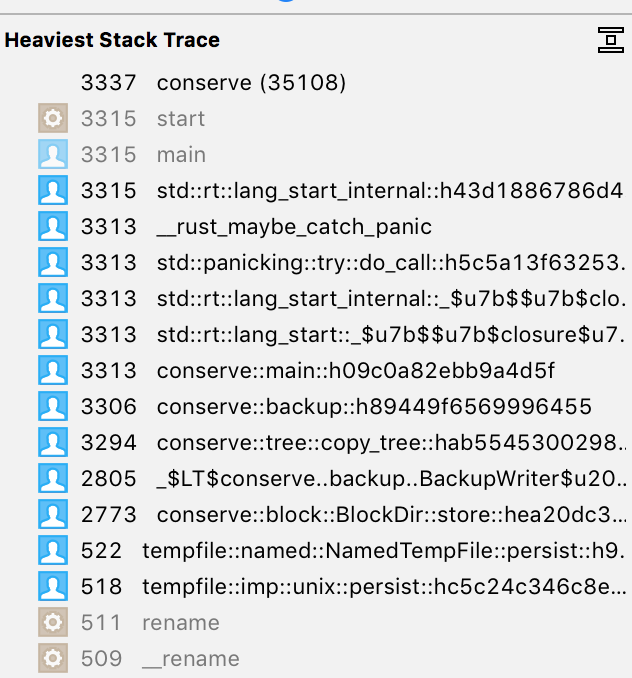
It seems faster running there than it does when I run it interactively, so
I don't know what's going on. Maybe painting the progress bar to the terminal
is slowing it down. I might add a --progress=no option.
I do notice a lot of time spent renaming files, which is perhaps a macOS
filesystem performance problem. Perhaps it'd be improved by more aggressive
threading so we can get other work done while it's trying to do the rename.
I'm somewhat waiting to see the Rust async/await thing settle out, and to
get core formats and structures right, before coming back to that.
The other thing that would help with that is combining small files into larger joined-up blocks...
cargo clippy now works well, so we don't need the option to build it in
any more.
I had a go at changing copy_tree to be a method on ReadTree but it
seemed to get too complicated to express the various associated types, and
I couldn't make it work properly.
I added a -v option to print filenames; I'm not sure if the Report/UI
structure is really quite right, but it's perhaps close. I want some kind
of context object that manages sharing/locking internally, I think.
🌴
(Santa Monica)
Still proceeding, very intermittently.
On reflection, the degree of duplication that'll come from having a block pool per band seems like a bad deal. Probably better to have just one per archive and to garbage collect from it carefully.
I'd also like conserve backup -v to print all the names of files being copied.
This seems to show the current ui object structure isn't quite right.
There is a tangle here of several concerns:
-
Capabilities of the terminal/whatever: can it erase output, can it do colors, etc?
-
User's preferences to show all filenames or not, show a progress bar or not.
I'd like to leave the door open to later doing a more full-screen curses interface or even a web server UI.
I looked into using futures-cpupool to speed up writes, since they're dominated by compression and hashing, both CPU-heavy. (At some points backups will block for IO, but it seems to be a minority of the time and so perhaps can be ignored for scheduling purposes.)
There's some experimental code in https://github.com/sourcefrog/conserve/commit/b79e7121ba61a4caf3a5e3944bdc9259c9737f47 but I realized it's proably not going to get enough parallelism to be really worthwhile. The files are passed in through the WriteTree trait and that's inherently one file at a time.
To really speed up writes, we probably need copy_tree to dispatch several files in parallel, through a Tree and WriteTree trait that's defined in terms of futures?
The other thing that trying this reinforced is that, of course, Rust is careful about what data can be shared or sent between threads, so the objects passed through futures must mostly be Sync and/or Send. Passing files or other such active or internally mutable objects isn't going to work well.
These marker traits aren't so well documented but are fairly easy to understand if you think about whether the underlying memory could be passed to another thread, or could be accessed by multiple threads concurrently.
Without doing that larger change, we could potentially parallelize storage of multiple blocks within a larger file. That might be a more rare case, and perhaps not a large performance win, but it might also be educational about threadpool concurrency in Rust.
There is a constraint on parallelizing within a file, which is that we store a whole-file hash and this must be calculated serially from the start. Perhaps this could be omitted but it seems useful protection against a bug in how blocks are handled.
So it's possible but it's a bit difficult to understand the error messages here. Perhaps the practical thing is to wait (hah) for async/await. Also it'll need a larger restructuring to do really well.
I got profiling working using Google pprof, per https://github.com/AtheMathmo/cpuprofiler#installation. That shows the majority of time, 69% of the time, is going into blake2b and snappy, which is kind of good in that I'm not wasting time with for example buffer copying, but also bad in that there's no obvious speedups.
cargo-profiler and Valgrind seems too broken by
https://github.com/kernelmachine/cargo-profiler/issues/32.
There is a blake2 option to use SIMD instructions, but only on nightly Rust, so I'd need to pass that through to a Conserve cargo feature.
I previously made a change to use Rayon to run blake2 hashing in parallel, in the limited case of long files that need to be separately hashed for the file and their blocks. That was a remarkably easy change and when running with it I think I see multiple cpu cores running in parallel, and at least there are multiple threads.
So it seems like the way forward for speed is:
-
Do incremental backups so we just don't have to write as much data!
-
Use Rayon, or maybe
futures-cpupoolto run multiple compression/hashing jobs in parallel. This will get a little more complicated when we want to compress multiple files in parallel, which will give more opportunities for overlapped work, but mean their results need to be joined together to fill the index, before the index itself can be written. It should be interesting. -
Add a feature, on nightly only, that uses
blake2SIMD.
We should also be able to readahead and decompress from StoredFile.
There's a complication in these which is that naive applications of these will tend to read the whole file into memory, which I don't want. We should read ahead as many blocks as are necessary to get best parallelization, probably n_cpus, but no more.
🎅
I added a StoredFile and StoredTree that abstract a bit from code such as
restore exactly how files are stored across blocks etc. This is intended as
a foundation for splitting files across multiple blocks and for incremental
backups.
☕
Backups are still surprisingly slow for the amount of work they're doing. I suspect maybe it's the still-remaining sync calls, or Brotli.
It'd be good to add some Rust benchmarks: it's just a little complicated by the fact the interesting ones must write at least to a tempdir.
So on the deflate branch a backup of the tree from ~/tmp/test-backup-input
on optimist takes
time ./target/release/conserve --stats backup ~/Backup/conserve.c4 .
2:56 1020 files 410 dirs 443MB => 171MB 62% 2.5MB/s 176.12 real 42.32 user 129.18 sys
By contrast cp of that tree takes
1.32 real 0.02 user 0.85 sys
So both the user and system time are too high. sync might account for the
system time. Or perhaps the hashes.
time find ~/tmp/test-backup-input -type f -exec b2sum '{}' \;
...
4.84 real 1.98 user 1.26 sys
So not trivial but still orders of magnitude less...
Also why are the stats not showing up? Because I need -v, and probably should
just make that imply --stats.
So that claims that the majority of the time is in block.compress:
Stats:
Counts:
block 977
block.already_present 50
dir 419
file 1027
index.hunk 2
source.selected 1446
source.visited.directories 419
Bytes (before and after compression):
block 444124441 171220928 62%
index 510908 128044 75%
Durations (seconds):
block.compress 136.646
block.hash 0.928
index.compress 0.107
index.encode 0.002
source.read 0.126
sync 0.514
178.69 real 42.49 user 130.95 sys
That report claims little time in sync which seems surprising, but the
measurement should be correct - unless it causes knock-on effects after the
function returns. And this is on SSD, it's probably much worse on HD.
Let's see how that looks on brotli - wow, remarkably faster!
Stats:
Counts:
block 980
block.already_present 47
dir 419
file 1027
index.hunk 2
source.selected 1446
source.visited.directories 419
Bytes (before and after compression):
block 444124711 136077557 70%
index 510908 91886 83%
Durations (seconds):
block.compress 10.768
block.hash 0.936
index.compress 0.016
index.encode 0.003
source.read 0.126
sync 0.402
15.80 real 12.41 user 2.60 sys
Inserting a BufWriter seems to help a lot:
Durations (seconds):
block.compress 27.183
block.hash 0.927
index.compress 0.106
index.encode 0.002
source.read 0.189
sync 0.483
By contrast just compressing all these files takes a while:
time find . -type f -exec gzip -c '{}' \; >/dev/null
25.97 real 22.63 user 1.64 sys
With a refactor of compression code to write to an in-memory buffer, it's unfortunately slower :/
Durations (seconds):
block.compress 30.150
block.hash 0.930
block.write 0.083
index.compress 0.110
index.encode 0.003
source.read 0.844
sync 0.475
Without that change,
Durations (seconds):
block.compress 27.653
block.hash 0.964
index.compress 0.111
index.encode 0.004
source.read 0.147
sync 0.466
33.04 real 26.96 user 3.71 sys
With early detection of already-present blocks:
I wonder if linking through flate2 to a C implementation would help this.
Stats:
Counts:
block 980
block.already_present 47
dir 419
file 1027
index.hunk 2
source.selected 1446
source.visited.directories 419
Bytes (before and after compression):
block 444124711 176384298 61%
index 510908 123277 76%
Durations (seconds):
block.compress 27.124
block.hash 1.123
block.write 0.107
index.compress 0.124
index.encode 0.004
source.read 0.224
sync 0.462
30.46 real 24.81 user 3.73 sys
Perhaps, writing everything to an in-memory buffer is causing excessive double-buffering and copying. Perhaps BufWriter is smarter about only buffering small writes?
With a BufWriter, not a really obvious change:
Durations (seconds):
block.compress 27.836
block.hash 1.024
index.compress 0.113
index.encode 0.002
source.read 0.219
sync 0.481
30.80 real 25.33 user 3.89 sys
I think eventually we either need a cheaper compressor, multi-threading of it, and to be smarter about not using it on incompressible files. However, many of these files are compressible, it's just a fair bit of data.
So this was overall 444MB in 30.8s elapsed, 14MB/s.
tar cz on the same directory writing to a file is
21.77 real 21.08 user 0.44 sys
25.47 real 22.14 user 0.66 sys
So we're 1.2x to 1.4x slower: not terrible but definitely room for improvement.
I'm still seeing the Brotli code as much faster, which is really surprising, completing this backup in less time and with substantially better compression:
Counts:
block 980
block.already_present 47
dir 419
file 1027
index.hunk 2
source.selected 1446
source.visited.directories 419
Bytes (before and after compression):
block 444124711 136077557 70%
index 510908 91886 83%
Durations (seconds):
block.compress 11.735
block.hash 0.991
index.compress 0.009
index.encode 0.002
source.read 0.145
sync 0.423
17.46 real 12.96 user 2.78 sys
Perhaps it's just due to linking in a highly optimized C compressor vs a perhaps more naive Rust flate implementation?
Trying flate2-rs does bring a big improvement although surprisingly still neither as fast nor as compact as Brotli:
Stats:
Counts:
block 980
block.already_present 47
dir 419
file 1027
index.hunk 2
source.selected 1446
source.visited.directories 419
Bytes (before and after compression):
block 444124711 147252049 67%
index 510908 123277 76%
Durations (seconds):
block.compress 22.407
block.hash 1.009
index.compress 0.118
index.encode 0.002
source.read 0.562
sync 0.418
25.88 real 22.99 user 1.22 sys
Going back to Brotli2 but in the new code structure, at level 9 it's a lot slower. At level 4, much faster.
OK so using flate2 with Compression::Fast makes it much faster and still
pretty good compression:
Bytes (before and after compression):
block 444124711 168512000 63%
index 510908 123277 76%
Durations (seconds):
block.compress 3.623
block.hash 0.984
index.compress 0.104
index.encode 0.001
source.read 0.248
sync 0.447
6.50 real 4.46 user 0.98 sys
So, honestly, given high compression is not an overriding priority, perhaps the simple thing is to stick with flate2 or deflate and just set it to be fast. At any rate that gives the user a lot of dynamic range and this can easily be exposed as an option.
It would be interesting to show a histogram of per-file compression ratios.
Let's try Snappy from https://docs.rs/crate/snap/0.2.2:
Stats:
Counts:
block 980
block.already_present 47
dir 419
file 1027
index.hunk 2
source.selected 1446
source.visited.directories 419
Bytes (before and after compression):
block 444124711 206257381 54%
index 510908 123277 76%
Durations (seconds):
block.compress 1.332
block.hash 1.024
index.compress 0.109
index.encode 0.002
source.read 0.760
sync 0.475
4.92 real 2.27 user 1.07 sys
So, distinctly less compression, but indeed pretty snappy, storing 88MB/s: and it's still reduced by a factor of 2x on this tree. I like that speed.
I'd suspect many backups will have many files that are poorly compressible anyhow.
I note from https://docs.rs/snap/0.2.2/snap/struct.Writer.html that their Writer does some buffering already, so we could remove that, and it uses the Snappy framing format which we might not want. Doing without them it's even a bit faster,
Durations (seconds):
block.compress 1.213
block.hash 1.037
index.compress 0.103
index.encode 0.002
source.read 0.238
sync 0.474
4.47 real 2.05 user 1.12 sys
Very surprisingly the BufWriter seems to be helping performance substantially vs writing direct to the NamedTemporaryFile, but I'll take it.
Durations (seconds):
block.compress 1.191
block.hash 1.008
index.compress 0.100
index.encode 0.001
source.read 0.228
sync 0.485
4.10 real 2.03 user 0.96 sys
🎅 💻 🎄
Progress bar and log messages are now nicely synchronized. It turns out there's
a bug in either Rust's term package or iTerm2 or both, which caused some
screen corruption. You can optionally see filenames go by with -v.
I'd kind of like to show the current filename in the progress bar and not scroll them all by, as Ninja and Bazel do. Perhaps that's not the most important, but:
- visible performance is sometimes as important as actual
- transparency is good for debugging
- knowing what's being backed up is useful
Also, turns out that some of the slow performance I saw on Windows 10 was due to the Windows Defender anti-virus. For now, may be easiest to turn that off for the archive directory, since it's unlikely to find anything interesting. That was in part due to the progress UI making it very obvious that machine was unexpectedly slow.
Write speeds were looking rather bad, only about 1-2MB/s on a fast machine. As an easy step towards that I have turned down Brotli compression from 9 to 4, which still seems to compress well and gives us ~40MB/s.
There's a lot more we can do there including compressing on multiple threads, which should be reasonably safe and straightforward in Rust, and skipping uncompressible files.
As it is at the moment though, on my Macbook Pro, tarring the conserve directory takes 8.2s and a Conserve backup takes 6.51s elapsed, and they are 66MB and 65MB respectively. So it's broadly OK.
Though, it still seems pretty slow on a slow ARM machine, with compression at only about 3MB/s. From benchmarks, gzip might be a better bet where compression speed matters, as it does here.
Other recent changes are switching from docopt to clap where the
declarations of the options are to my taste a bit easier to maintain and it
gives nice help for subcommands.
Conserve now always flushes files to disk as they're written. What I'm trying to avoid here is, after a crash or sudden power loss, having an index file that shows that certain files have been backed up, but the data files for them were lost.
Unless Conserve walks all the data files when resuming, which would be slow, it won't notice this. (And really it would have to check their contents not just that they exist.)
Happily it turns out that sync on every file is pretty cheap according to
conserve --stats, taking <0.1s even in a whole backup taking many tens
of seconds. I have not yet tested on Windows or with a magnetic disk though.
For the terminal UI, we need one object that synchronizes log messages with the progress bar (#52).
Restore now restores symlinks.
I'm thinking perhaps in-process integration tests against the API would be a good idea. That requires building a library not just a binary, which might break Clippy. But Clippy is nice but not critical.
(Rainy day in California.)
I got a progress bar going, showing the count of files and directories stored, bytes, compression, rate etc.

This also should be unified with the code that writes log messages to the screen, so they can be synchronized. Also updates about files saved should be part of the progress UI probably not log messages, or not just log messages. Perhaps logging progress counts as a different UI for non-terminal cases.
One thing this makes obvious, and that makes it worth having it, is that the rate of storing the backup is not all that good for the speed of machine I'm testing on: maybe this is due to using Brotli and we should try gzip.
(In Maui.)
I split out a conserve_testsupport subcrate to avoid copied code between the main
unit tests and the blackbox tests. This actually feels a bit cleaner than having
them import a conserve library, as I previously was, since it limits what
dependencies can exist.
Discovered something nice in a0b0a76, which is that ScratchArchive can implement
Deref and directly act as an Archive, while still knowing to clean up after
itself.
Also new today: stats printed nicely, checks that all counters are registered, and Conserve skips rather than failing on symlinks in the source tree.
(In Philz Redwood City.)
Decided backing up multiple directories into a single archive is complicated and probably not that useful: the pint is to backup a single tree. Am pulling that out.
Did a little update to the man page: is that still the most useful place to store info? Probably not these days. Probably either html or just built-in help is better.
BandId is now comparable, and archives can now hold more than one band,
which makes them much more useful. BandId::next_sibling makes them nicely
arithmetic.
I tried refactoring Archive::list_bands into an iterator, but it makes it
more complicated for no clear benefit, so abandoned this.
Happy birthday, America! 🇺🇸🎆
Lots of recent progress: all small, but moving.
I changed Band from holding a reference to the containing Archive to just
knowing its own path. It avoids explicit lifetimes and perhaps is a cleaner
layering anyhow.
Now have index hunks. Getting close to being able to actually make a backup. Now to create a band, add some files both to the data blocks and to the index.
I moved the blackbox tests away from relying on Python Cram
to just running conserve as a subprocess from Rust.
Seems fine.
Also now have Conserve storing the data for files though not yet adding them to the index or anything else that would let them actually be retrieved.
The backup.rs code is
now storing
very approximately what I need, in roughly the right format. Needs some
clean up to cope with storing multiple files the right way.
Maybe the command should be restricted to conserve backup ARCHIVE SOURCE, and
if you want to select things inside that source that can be done with
exclusions. That will make it simpler to get the right ordering.
I tried having a common Report trait abstracting whether the report is self-synchronizing or not.
However it doesn't work for an interesting reason: the whole thing about the SyncReport is that
it can be updated even through a non-mutable reference, whereas the simple Report needs a mutable
reference. The trait can't abstract across them. Java and maybe C++ would gloss over that
by not having such strict concepts of mutability.
Passing a &mut report in to the methods does work and seems cleaner, though.
Another fun weekend of development: I added comparison and sorting of archive internal paths. That feels very elegant in Rust.
There are also now counters of IO, errors, compression, etc. This brings explicit lifetimes back in to the picture, because the BlockDir holds a reference to a SyncReport constructed by the caller. I really dislike how this necessitates every function declared in the impl to have &'a noise, even if it does nothing with 'a. But really my unhappiness comes from not knowing whether this is idiomatic Rust or whether there's some simpler way to write it.
Idea: Alternatively, just pass a &mut report in to every function that will uses it. Avoids marking lifetime.
I made a SyncReport that implicitly locks around each update. It's nice that's possible and it seems like good layering but at the moment with no threads in the picture it seems expensive. Another option here would be a trait that hides from the receiver whether the Report synchronizes or not.
I realized also that the approach of combining small files into blocks is cause a slight complication to writing the index: we don't know the hash in which the file is stored, immediately when it is stored. We need a pipeline of some number of files that all go into blocks, and then later make their addresses available.
Next:
- refactor counters
- start adding an index
- maybe a
conserve cat-blockcommand?
The contents of backed-up files are stored in compressed, hash-addressed block files. (See: doc/format.md.)
This tries to balance a few considerations:
For cloud data stores we want files that are not too small (too many round trips) and not too big (too slow to write.)
I want large files that are changed in place, such as VM images or databases, to be incrementally updated and not entirely rewritten when they change. However the rsync rolling-sum approach used in Duplicity is not necessary, and has a security risk: insertions into files, moving the rest of the data along is rare for large files. So Conserve uses a degenerate case of rdiff: it matches only data with the same strong hash, aligned on a block boundary.
The start of this is implemented in
a simple BlockWriter
class
that compresses and accumulates the hash of what was written to it.
The question arises here of whether it's OK to buffer compressed
data in memory, and I decided it is: writing blocks to temporary
files will be tedious, and the size we want for good IO should
fit in memory on typical machines. (Let's say, 1GB or less.)
In writing this I realized the description of versioning semantics was not so clear and consistent, so I updated that in d09d08c.
Next up is to actually write blocks into a block storage directory, and then we can start writing these into bands, the next larger storage structure.
One dilemma here is whether to put blocks into subdirectories, or to have one directory with a potentially very large number of block files. Choosing at runtime makes it harder to know where to look for a particular file, and makes things more complicated. On most modern filesystems there is no direct limit, but I would like the option to backup to flash sticks which have a limit in FAT. I'll use the first three hex chars, for 4096 direct child directories, each of which can have many files.
Am trying the Rust Clippy linter, but it won't work at the moment because this package provides both a library and binary.
Lifetime management in Rust continues to throw up thought-provoking errors, but
in many cases they are pointing to a real imprecision in the code.
In the case of the BlockWriter the object should be consumed as it finishes.
In another language, the object would remain in a state where it can be called,
but should not be.
Storing blocks into a data directory is now done in
3bf3190.
I was going to tell the BlockWriter how to store itself, but it turns out
cleaner to have a separate
BlockDir
which knows about the directory structure and consumes the BlockWriter.
Rust lifetimes, again, are awkward at first but create positive design pressure.
if let
is nice here for error handling: if create_dir returns an error and the error is not
AlreadyExists, return it.
I started using a type alias, type BlockHash = String
to be more descriptive in the API. It's interchangeable with a regular String.