An extreme case of environment with more than 30K minions using a single SUMA server (bsc#1137642)
Bug report: https://bugzilla.suse.com/show_bug.cgi?id=1137642
- SaltReqTimeoutError: Message timed out
- StreamClosedError
- SaltClientError (salt-api)
- python3 invoked oom-killer
- reaching max open files (sockets)
- Resource temporarily unavailable (src/thread.cpp:119) - coredump from salt-api
- Exception occurred while Subscriber handling stream: Already reading
- Batch Async was working fine in normal conditions, one challenge was to reproduce the problem
- Memory leak on the Salt "EventPublisher" process when running Batch Async calls
- Recreation of IOLoop on each Salt Batch Async call
- Bad coroutine exception handling produces infinite loop
- A lot of minions connected directly to salt-master (not through a proxy)
- Reaching max open files
The problem could be reproduced by using a master and two minions and sending a lot of requests to salt-api:
# cat /tmp/request.data
{
"client": "local_async",
"eauth": "auto",
"username": "admin",
"password": "admin",
"tgt": "*",
"fun": "cmd.run",
"arg": ["sleep $((RANDOM % 60)) && head -c 500 </dev/urandom | base64"],
"timeout": 30,
"gather_job_timeout": 15,
"batch_delay": 1,
"batch": "1"
}
# while true; do curl -X POST -H "Content-Type:application/json" -d @/tmp/request.data localhost:9080/run; echo "\n"; sleep 1; doneWe used memoryprofiler in order to monitor the memory consumption of the "salt-master":
- Install
python-setproctitleto attach the Python process name as the process context. - Run
mprof.py run -T 1 -M salt-master -l debugto monitor the "salt-master" process every 1 second. - Generate a graph with collected data:
mprof.py plot -o plot.png
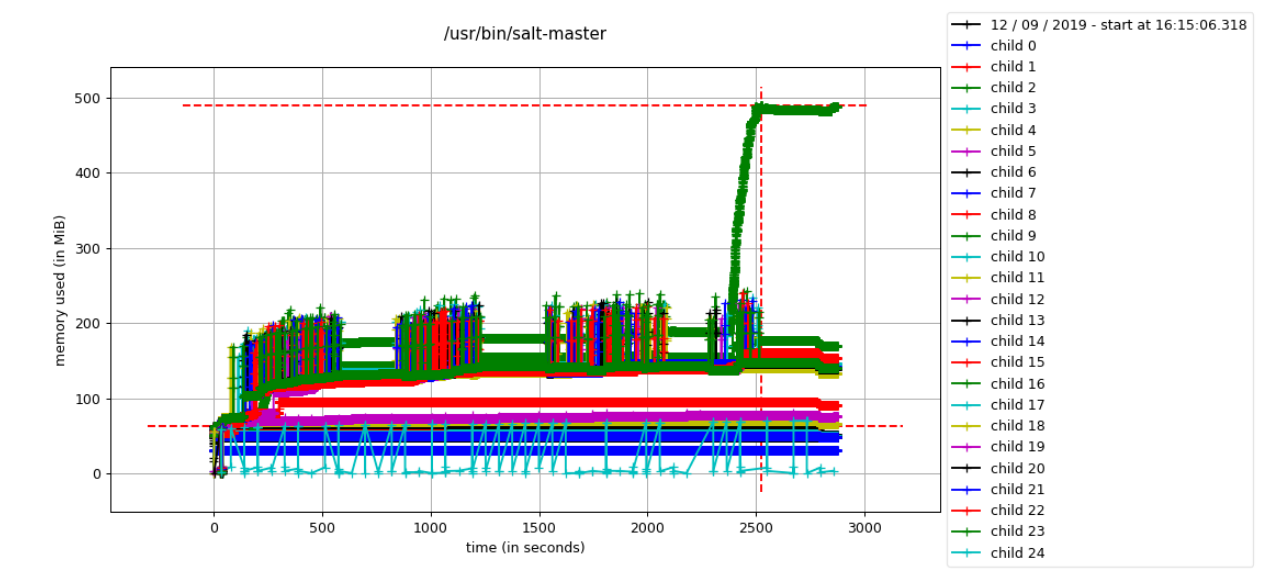
- Isolate the "EventPublisher" process:
mprof.py plot --pattern '.*EventPu.*' -o plot.png
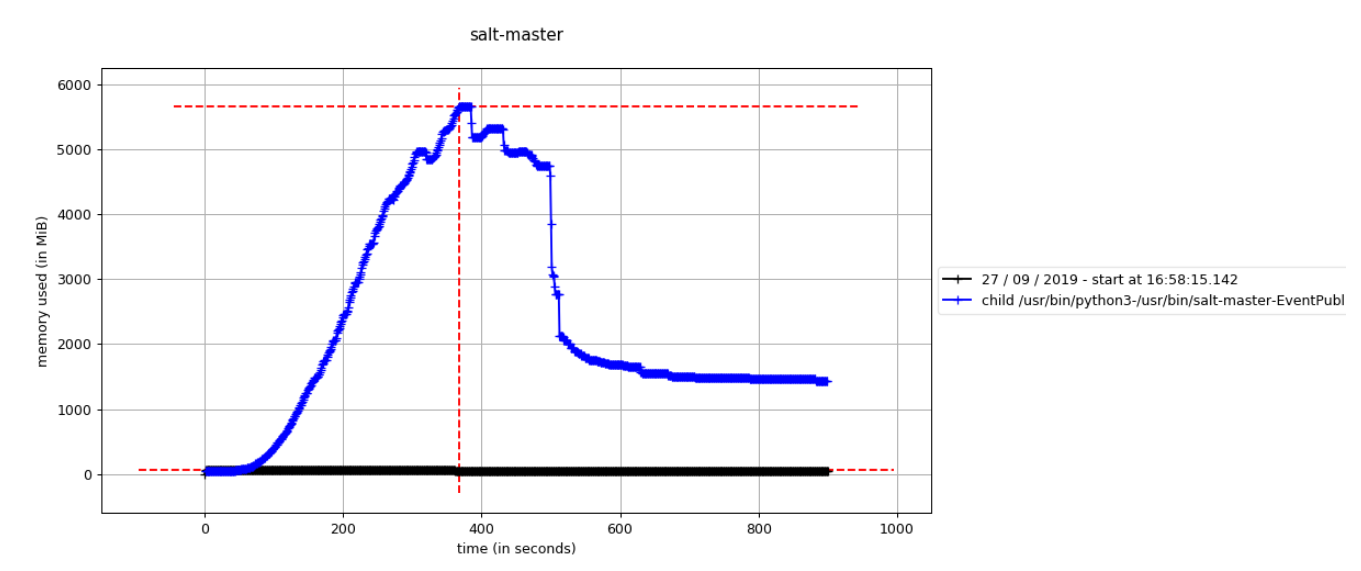
After a few rounds of debugging the Batch Async code, we figured out that in cases where the minions were in an unresponsive state (eg: out of memory) the returns from the saltutil.find_jobs targeting those minions were not interpreted correctly. This was leading to an ever increasing number of saltutil.find_jobs. After fixing this initial issue, the leak disappears but the memory consumption was still pretty high when we run our highload tests of Batch Async calls.
Another problem was that the same JID was used for the internal batch-async saltutil.find_jobs (in order to make it easier to track them). This worked ok under normal load but had issues when a lot of saltutil.find_jobs were in-flight (eg: in the situation described above). The fix was to use different JIDs.
We also noticed that, under heavy loads, the "salt-master" starts behaving not so smooth. The events on the Salt Event Bus were not continuously published but instead a bunch got published and then it seems the "salt-master" gets stuck for some seconds to end up publishing another bunch of events.
These symptons made us to realize that there was a problem with the Salt IOLoop that handles all Salt coroutines. Finally we realized that we were recreating different instances of the IOLoop instead of reusing the same single one that Salt used. This makes the different IOLoop to compete with each other resulting in some coroutines getting stuck when a different IOLoop has the control.
Particularly, the Batch Async code instantiate a LocalClient in order to perform underlying Salt jobs that are required for a Batch Async execution (like test.ping and saltutil.find_jobs).
It's very important to explicitly pass the current IOLoop when instantiating the LocalClient:
ioloop = tornado.ioloop.IOLoop.current()
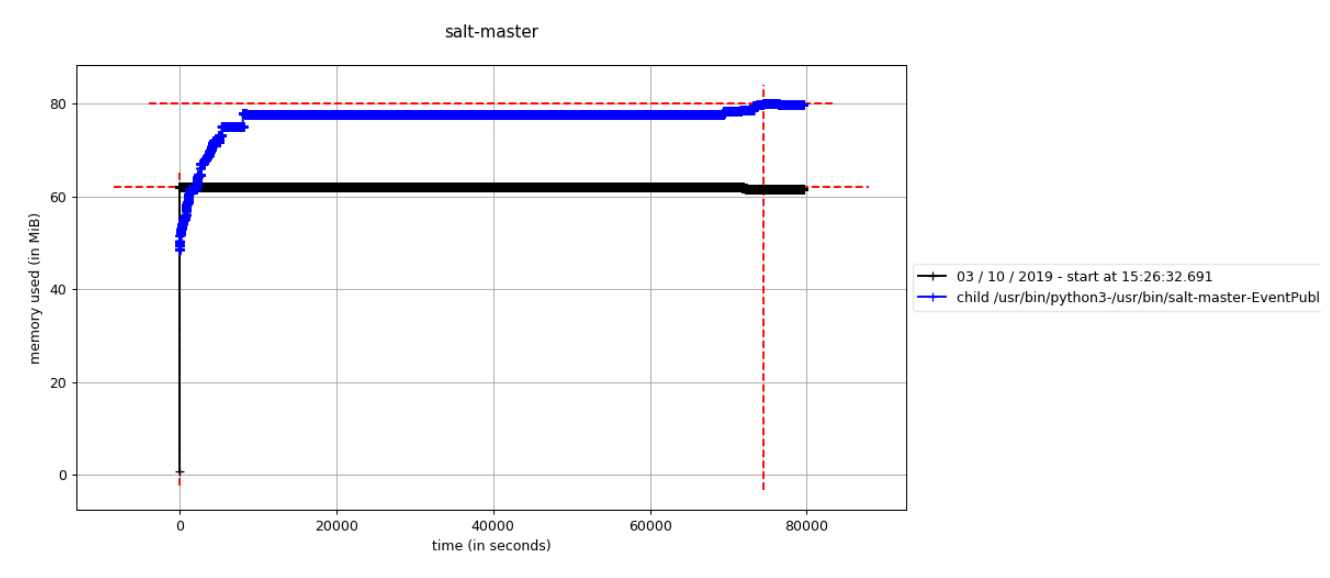
self.local = salt.client.get_local_client(parent_opts['conf_file'], io_loop=ioloop)After reusing the main Salt IOLoop when performing Batch Async calls, the memory consumption dramatically drops for the same highload tests:
Using worker_threads: 500 produced the "reaching max open files" issue in combination with having a lot of minions directly connected to "salt-master".
The solution was to reduce worker_threads to 120 and to exclude the directly connected minions by allowing only the proxies IPs in iptables.
The memory issue has been fixed now, but our customer "E" is now getting some floods of exception messages that makes the "salt-master" completely unstable and unresponsive after some time running:
2019-09-30 12:39:10,415 [salt.transport.ipc:772 ][ERROR ][505] Exception occurred while Subscriber handling stream: Already reading
We were not able to replicate this issue locally, and according the our tests and the behavior on the customer side, this smells like a race condition that is produced on the customer side due the high number of minions (more than 30K). When there are such number of minion, the race condition is easily faced and that makes the "salt-master" to become unstable.
After deeply looking and understanding the ipc code, we noticed a bad exception handling inside a coroutine:
- Before the fix:
@tornado.gen.coroutine
def _read_async(self, callback):
while not self.stream.closed():
try:
self._read_stream_future = self.stream.read_bytes(4096, partial=True)
self.reading = True
wire_bytes = yield self._read_stream_future
self._read_stream_future = None
self.unpacker.feed(wire_bytes)
for framed_msg in self.unpacker:
body = framed_msg['body']
self.io_loop.spawn_callback(callback, body)
except tornado.iostream.StreamClosedError:
log.trace('Subscriber disconnected from IPC %s', self.socket_path)
break
except Exception as exc:
log.error('Exception occurred while Subscriber handling stream: %s', exc) As you can noticed on the above code, this a coroutine containing a while loop that always tries to read the stream when it's open. The exception happens when the stream is being already reading, in this case, a exception is produced and the coroutine continues the execution trying to read the stream again.
The problem here is that this coroutine is never releasing its execution to the IOLoop, in order to other coroutines to complete their executions (like reading the stream). We need to force some yield gen.sleep() to release the execution of this coroutine to the IOLoop while sleeping, so other coroutine can finish.
- After the fix:
@tornado.gen.coroutine
def _read_async(self, callback):
while not self.stream.closed():
try:
self._read_stream_future = self.stream.read_bytes(4096, partial=True)
self.reading = True
wire_bytes = yield self._read_stream_future
self._read_stream_future = None
self.unpacker.feed(wire_bytes)
for framed_msg in self.unpacker:
body = framed_msg['body']
self.io_loop.spawn_callback(callback, body)
except tornado.iostream.StreamClosedError:
log.trace('Subscriber disconnected from IPC %s', self.socket_path)
break
except Exception as exc:
log.error('Exception occurred while Subscriber handling stream: %s', exc)
yield tornado.gen.sleep(1)As you can see now, when the exception is produced, the execution is delegated to other coroutines during 1 second, allowing the stream to be read, so on the next iteration of the while loop, the exception won't be produced.
After this last fix, the "salt-master" was able to handle the load produced by those 30K minions flawlessly and keep running smoothly without getting stuck and with a low memory consumption on the "EventPublisher" (around 80MB).
- Memory leak on Salt Batch Async: https://github.com/openSUSE/salt/commit/6af07030a502c427781991fc9a2b994fa04ef32e and https://github.com/openSUSE/salt/commit/002543df392f65d95dbc127dc058ac897f2035ed
- High memory consumption of Batch Async (reuse ioloop): https://github.com/openSUSE/salt/commit/55d8a777d6a9b19c959e14a4060e5579e92cd106
- "Already reading" exception: https://github.com/openSUSE/salt/commit/6c84612b52b5f14e74a1c44f03d78a85c6f0c5dc