
- Purpose of this guide
- Applying
- Helpful Links 📎
- The Behavioral Interview 📞
- Technical Questions Overview 🔬
- Programming Languages 📜
- Tools 🧰
- SQL / NoSQL
- Relational Databases
- CI/CD 🚀
- API Design
- HTTP
- AWS ☁️
- Software Testing 🛠️
- Parallel Processing 🧵
- System Design 🏗️
- Statistics and Probability 🍀
- Data 📊
- ML Prep 🧠
- NLP ✍️
- TODO: this is a WIP

📖 This guide is intended to provide short info snippets on a variety of coding topics and the interview process.
🧗 I hope you pass your interviews, become a better programmer, and land your dream job!!
📃 Look up Mayuko and Ken Jee for the best resume advice.
General guidelines include: keeping it to one page, demonstrating impact at past positions, fitting your skills to a job, and demonstrating knowledge of tools and languages.
- Best times to apply
- How recruiting works in tech (video)
- How to find Software Engineering job openings (video)
Good application sites include:
- Linkedin has expensive job postings so mostly big companies are posting and they are quite competitive.
- Consider using Indeed
- Tripe Byte: A resource to 'pre'-interview
- Wellfound: the best startup search tool
- Canvas, Smartr, The Muse
Try to add keywords to your linkedin profile, and make sure it is kept up to date. Recruiters will come to you and it is a great way to get a foot in the door. Pay attention to job descriptions and try to learn the skills and technologies to make yourself relevant to the field you would like to get into. Additionally reaching out through a well thought out message to a recruiter or manager may help you get an interview.
Motivation
- How to study everyday (video)
- How to focus on learning (video)
- 📚 Atomic Habbits by James Clear
Mayuko how to land a SWE internship (video)
Nicholas how to land a SWE internship (video)
Tina Ultimate Guide to a Data Science internship (video)
🎉 Congratulations!! 🎉
Negotiating an offer (video)
Levels.fyi
⭐ Creating and working on meaningful personal projects is incredibly important towards demonstrating your experience.
Expanding your resume/portfolio:
- 🧠 Kaggle
- Creating a RESTful API
- Web applications (with persistent memory)
- 📊 SQL analysis (tableau, powerbi)
 Contributing to open source projects
Contributing to open source projects
Portfolio Resources:
Build a Data Science portfolio playlist (videos)
More Data Science portfolio tips (video)
Software Engineering Projects and tips (video)
- Leetcode - best technical problem source 👈 use this!!
- Codewars: easier problems
- Mode (SQL)
- StrataScratch
- Coding Interview Help
- Related Interview Help Flash Cards
- CS Guide: lots of articles and books
- A CS Interview Guide: very short
- Interactive Coding Challenges
- System Design Primer 🏗️
- The Complete FAANG Preparation
- Data Science Interview Resources
- Great Big Data Cookbook
- ML Interview 🧠
- DevOPs Guide 🐳
- Sites Every Programmer Should Visit
- Build Your Own X
- Learning Roadmaps 🗺️
- Project Based Learning
- Free Programming Books 📚
Truly Random Articles
How a browser works
Raft Article
Code Review Best Practices
Expectations of a Junior Developer
A Billion Cheat Sheets on Everything
Google Learning
Dev Tool Websites
Color Gradient Generator Website 🎨
Hidden Dev Tools Website
Simple Icons
Shield Badge Creator
Places to find another person to practice interview with: 🎤
Example Coding Interviews: 📽️
Nick White Java Leetcode Playlist
Google Coding Interview with a normal SWE
JavaScript interview with a Google engineer
Python interview with a Google engineer: Coin Change

📞 Most behavioral interviews are short inquiries into your experience and character.
They may throw in some technical 'trivia' questions on things they are looking for.
Some behavioral interviews also involve walking through a past project or two. Make sure to maintain good documentation and understand every part of your past projects.
Tell me about yourself:
- Current Role (your headline)
- College
- Post College / Current Role
- Outside of work (how are you upskilling)
- optionally: Career goal and/or a unique fact about yourself
What do you know about ___ and why did you decide to apply here? What drew you to us?
- Research company you're applying to, look at:
- Work environment
- Growth potential
- type of work
What makes you a good fit for the company?
What are the things that are most important to you in a job?
When answering a question about a past experience it is best to use either a nugget first method or the STAR method to best tell the tale.
Nugget first: Start with a nugget that succincly describes what your response will be about.
STAR method: Situation / Task -> Action -> Result
Tell me about a time where you had to persuade a group of people to make a change.
Describe a conflict you had with a team member. How did you handle the conflict and what was the outcome?
Tell me about a time where you dealt with ambiguity.
Tell me about a time where you demonstrated leadership skills.
What do you do when faced with adversity?
How do you handle working under pressure?
Do you enjoy working alone or on a team more?
How would your boss describe you?
Tell me your greatest strength and weakness.
How do you approach a new project and technology? 🧪
- Look at similar project examples
- Examine why they used the technology
- Read documentation explaining things
- Get hands on and try tutorials and experiment
💬 It is important to ask questions during and at the end of an interview, try one of these:
- What would my normal day look like?
- Can you tell me about whom I will be working with?
- How is mentorship approached?
- What would be your definition of success for this role?
- What is your tech stack?
- Do you enjoy your role in the company? What do you enjoy about your job?
- Do you like your company?
- What brought you to this company?
- Remote work?
- What are the standard working hours?
- How long is the interviewing process?
- What is the growth potential for me?

🔬 A technical interview usually consists of solving two problems infront of another engineer on a whiteboard or through a take home assessment with 3+ problems.
It is integral to talk to the interviewer through the problem and your thought process.
Understanding Big-O notation will also help you in the interview and to be a better programmer.
Learn your data structures and algorithms!!
📚 I would suggest using the book Cracking the Coding Interview and Leetcode for technical practice
Here is my problem solving process:
1. Listen to the problem and take notes
2. Create a good complex example to walk through by hand
3. Work out a brute force solution, then ask if they want you to implement it
4. Optimize your solution and walk through a few examples (psuedo code if you want)
5. Implement beautiful (efficient, simple, readable) code
6. Try to find edge cases
5 Problem Solving Tips for Cracking Coding Interview Questions
I have found technical trivia sometimes thrown into behavioral interviews; these are some of them.
What is an Object and a Class, what's the difference between them?
- A class is a template for objects. A class defines object properties and behaviors, including a valid range of values, and a default value
- An object is a member or an "instance" of a class. An object has a state in which all of its properties have values that you either explicitly define or that are defined by default
What are the pillars of OOP?
- Abstraction- ability to hide things
- Encapsulation- binding data and functions for protection
- Inheritance- inheriting features of parent class
- Polymorphism- the ability to redefine methods for derived classes
What is method overloading and overriding?
Overloading: when two or more methods in the same class share a name, but not parameters
Overriding: When name and parameters of method are the same
What is the difference between a method and a function?
- A function is a set of instructions or procedures to perform a specific task.
- A method is a set of instruction associated with an object and is continaed within a class.
Recursion:
- A function which calls itself recursively
- Consists of a base case (stopper) and a recursive case(recurser)
What's the difference between a stack and a queue?
- Stacks "pop" data off the stack, using last-in first out (LIFO) (ex: books/pancakes)
- Queues use first-in, first-out (FIFO) (think of a pipe)
What is the call stack? also look into: Memory Management
Can you explain dynamic vs static typing and strong vs weak typing?
Static - Data Types are checked before execution.
Dynamic - Data Types are checked during execution.
In a strongly-typed language, such as Python, "1" + 2 will result in a type error since these languages don't allow for "type-coercion" (implicit conversion of data types). On the other hand, a weakly-typed language, such as Javascript, will simply output "12" as result.
Can you explain declarative vs imperative programming?
Compiled vs interpreted?
An Interpreted language executes its statements line by line. Languages such as Python, Javascript, R, PHP, and Ruby are prime examples of Interpreted languages. Programs written in an interpreted language runs directly from the source code, with no intermediary compilation step.
🩺 What do you look for when reviewing code?
- B ottlenecks
- U nnecessary work
- D uplicated work
What is the difference between divide and conquer and dynamic programming?
⭐ This is likely the most important section for a technical interview. Mastering your data structures and algorithms will help you solve any problem thrown at you. It may help to implement each, but understanding how each will help you solve a problem is the most important factor.
I have sorted these based on their frequency/utility in technical interviews.
- Big O Notation: 👈 super important
⏲️ Big O notation is the language we use to describe the effieciency of algorithms (time and space complexity). It usually is used to describe the expected scenario. For example, quick sort will run in O(n) time on a sorted array, O(n^2) worst case, and O(nlogn) on average. Big O roughly describes calcuations in an iteration, dropping constants and non-dominants.
- Arrays/Lists/Strings:
- Two Pointers:
- Sliding Window:
- Hashing/Dictionaries:
- A hash table is a data structure that maps keys to values for highly efficient lookup
- Recursion:
Recursive solutions (mentioned above) are good for writing simple code, but can be very space inefficient. They can all be implemented iteratively.
- Know how to efficiently solve Fibbonacci
- BFS and DFS:
- Trees 🌳:
- Note: learn binary tree traversal
- Linked lists: A linked list is a data structure that represents a sequence of nodes. A singly linked list is a sequence of data elements, which are connected together via links (pointers). A doubly linked list gives each node pointers to both the next node and the previous node.
- Stacks 🥞: Last in first out (LIFO)
- Heaps / Priority Queues: Queues(FIFO), pydocs heapq
- Binary Search:
- Binary search Leetcode article: binary search is more useful than you think ⚡
- Divide and Conquer: Divide and Conquer works by dividing the problem into sub-problems, conquer each sub-problem recursively and combine these solutions. Dynamic programming is its extension.
- Dynamic Programming: Dynamic programming is mostly the process of finding overlapping subproblems and caching results for later(memoization). (ie solving recursive problems iteratively and/or with caching)
- Greedy Algorithms: Chooses the closest optimum is chose at each step to achieve the best solution.
- Backtracking: Backtracking is a technique that considers searching every possible combination for solving a computational problem. It is known for solving problems recursively one step at a time; if its not on the right 'path' it backtracks. Backtracking is a refined brute force approach which is generally used when there are possibilities of multiple solutions.
- Union Find:
- Graphing:
- Sorting Algorithms: (Quick, Merge, Selection, Tim)
You aren't likely to be asked to implement these, but knowledge of their runtimes is useful - Bit Manipulation: CTCI places these in high importance, but I do not think they are asked that often
- SQL:
Interviewing for data science and data analytics roles, I have found sql questions thrown in. They will tell you if its in the interview.

🐍 Python is a high-level, interpreted, dynamically typed, general-purpose programming language.
🗒️ Python is my go to technical interview language as it is beatiful, pythonic, and relatively easy. I highly recommend you learn it and use it in your interviews.
Python has the following data types built-in by default, in these categories:
Text Type: str
Numeric Types: int, float, complex
Sequence Types: list, tuple, range
Mapping Type: dict
Set Types: set, frozenset
Boolean Type: bool
Binary Types: bytes, bytearray, memoryview
What are lists and tuples and what are their differences?:
- Both sequence data types (can hold multiple types)
- Lists are mutable (changeable)
- Tuples are immutable
Understanding list comprehensions and slicing will make your life a lot easier. As well as https://docs.python.org/3/library/itertools.html
Lambda is an anonymous function in Python that can accept any number of arguments, but can only have a single expression. It is generally used in situations requiring an anonymous function for a short time period.
__init__ is a constructor method in Python and is automatically called to allocate memory when a new object/instance is created. All classes have an __init__ method associated with them. It helps in distinguishing methods and attributes of a class from local variables. This is also an example of a dunder method (double underscore) which is used to override something.
Self is a keyword in Python used to define an instance or an object of a class. In Python, it is explicitly used as the first parameter, unlike in Java where it is optional. It helps in distinguishing between the methods and attributes of a class from its local variables
Decorators in Python are essentially functions that add functionality to an existing function in Python without changing the structure of the function itself. They are represented by the @decorator_name in Python and are called in bottom-up fashion.
Here are some: https://docs.python.org/3/library/functools.html
*args can be used to pass multiple positional arguments (tuple)
**kwargs can be used to pass multiple keyword/named arguments (dict)
Functions are first-class objects. This means that they can be assigned to variables, returned from other functions and passed into functions. Classes are also first class objects. Note arguments are passed by reference. Read these builtin functions
Understand namespaces and scope.
PEP8: Python Enhancement Proposal. It is a set of rules that specify how to format Python code for maximum readability.
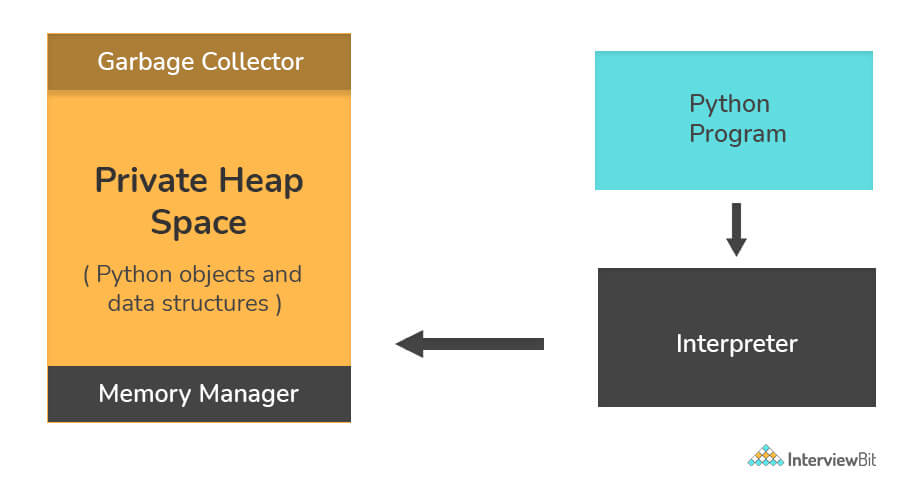
How is memory managed in Python?
Memory in Python is handled by the Python Memory Manager. All Python objects are stored in a private heapspace dedicated to Python, which is mostly inaccessible to the programmer. Python has built-in garbage collection to recycle unused memory.
class hi:
def helloWorld():
print('Hello World!')
helloWorld()Python Interview Questions
All hail Stefan Pochmann 👈 the king of pythonic code
Google python style guide

JavaScript is a high level dynamically typed interpreted oop language that is single threaded. Multiparadigm language supports: event-driven, functional, and imperative programming styles.
JavaScript sets the behavior of web pages.
What is the difference between let and var?
- The let statement declares a block scope local variable. Hence the variables defined with let keyword are limited in scope to the block, statement, or expression on which it is used. Whereas variables declared with the var keyword used to define a variable globally, or locally to an entire function regardless of block scope.
Events are "things" that happen to HTML elements. When JavaScript is used in HTML pages, JavaScript can react to these events.
What is a prototype in javascript?
- All javascript objects inherit properties and methods from a prototype.
What is the meaning of the keyword this in javascript?
- This is a reference to the object it belongs to
What is a promise and what is a callback?
- A promise is an object that may produce a single value some time in the future with either a resolved value or a reason that it’s not resolved(for example, network error). It will be in one of the 3 possible states: fulfilled, rejected, or pending.
- A callback function is a function passed into another function as an argument. This function is invoked inside the outer function to complete an action.
What is a first class function?
What does === do in JavaScript?
- checks strict equality: if two operands are different types returns false
console.log('1' === 1);
// expected output: falseJavaScript embedded in HTML:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>JavaScript Hello World Example</title>
<script>
alert('Hello, World!');
</script>
</head>
<body>
</body>
</html>JavaScript Interview Questions
JavaScript Interview Questions and Answers
5 Must Know Interview Questions for Javascript (video)
30 Seconds of Code
Awesome Interview Questions

☕ Java is a high-level, class-based, object-oriented programming language that is designed to have as few implementation dependencies as possible. It is a general-purpose programming language intended to let application developers write once, run anywhere (WORA)
Unlike C++, Java does not support operator overloading or multiple inheritance for classes, though multiple inheritance is supported for interfaces.
The keyword public denotes that a method can be called from code in other classes, or that a class may be used by classes outside the class hierarchy. The class hierarchy is related to the name of the directory in which the .java file is located. This is called an access level modifier. Other access level modifiers include the keywords private (a method that can only be accessed in the same class) and protected (which allows code from the same package to access). If a piece of code attempts to access private methods or protected methods, the JVM will throw a SecurityException
The keyword static in front of a method indicates a static method, which is associated only with the class and not with any specific instance of that class. Only static methods can be invoked without a reference to an object. Static methods cannot access any class members that are not also static. Methods that are not designated static are instance methods and require a specific instance of a class to operate.
The keyword void indicates that the main method does not return any value to the caller. If a Java program is to exit with an error code, it must call System.exit() explicitly.
The method name main is not a keyword in the Java language. It is simply the name of the method the Java launcher calls to pass control to the program. A Java program may contain multiple classes that have main methods, which means that the VM needs to be explicitly told which class to launch from.
What is a singleton class in java?
- A singleton class is a class that can have only one object (an instance of the class) at a time. After the first time, if we try to instantiate the Singleton class, the new variable also points to the first instance created.

public class HelloWorldApp {
public static void main(String[] args) {
System.out.println("Hello World!"); // Prints the string to the console.
}
}Java guides by Baeldung
Java interview quesitons
📓 Companies are looking for java developers with knowledge on Springboot, Maven, and Gradle
C is a statically and weakly typed, general-purpose, procedural computer programming language supporting structured programming, lexical variable scope, and recursion. It is an imperative procedural language designed to be compiled to provide low-level access to memeory and language constructs and thus machine instructions.
C uses pointers to 'point' toward an address or location of an object/function in memory.
Memory management
One of the most important functions of a programming language is to provide facilities for managing memory and the objects that are stored in memory.
C provides three distinct ways to allocate memory for objects:
- Static memory allocation: space for the object is provided in the binary at compile-time; these objects have an extent (or lifetime) as long as the binary which contains them is loaded into memory.
- Automatic memory allocation: temporary objects can be stored on the stack, and this space is automatically freed and reusable after the block in which they are declared is exited.
- Dynamic memory allocation: blocks of memory of arbitrary size can be requested at run-time using library functions such as malloc from a region of memory called the heap; these blocks persist until subsequently freed for reuse by calling the library function realloc or free
# include <stdio.h>
int main(void)
{
printf("hello, world\n");
}note Cython exists and is v cool

C++ is a general-purpose language with OOP, generic and functional features. I has access to low-level memory manipulation and is an extension of C ("C with classes").
C++ has two main components: a direct mapping of hardware features provided primarily by the C subset, and zero-overhead abstractions based on those mappings.
Stroustrup describes C++ as "a light-weight abstraction programming language designed for building and using efficient and elegant abstractions"; and "offering both hardware access and abstraction is the basis of C++. Doing it efficiently is what distinguishes it from other languages."
As in C, C++ supports four types of memory management: static storage duration objects, thread storage duration objects, automatic storage duration objects, and dynamic storage duration objects.
#include <iostream>
int main()
{
std::cout << "Hello, world!\n";
}
Scala is a strong statically typed general-purpose programming language which supports both object-oriented programming and functional programming. Designed to be concise, many of Scala's design decisions are aimed to address criticisms of Java
imo its shorter but more complicated Java code. It can perform faster than Java with tail recursion.
object HelloWorld extends App {
println("Hello, World!")
}
The Bourne Again SHell (Bash) is a Unix shell and command language.
It offers functional improvements over sh for both programming and interactive use. In addition, most sh scripts can be run by Bash without modification. The improvements offered by Bash include:
- command-line editing,
- unlimited size command history,
- job control,
- shell functions and aliases,
- indexed arrays of unlimited size,
- integer arithmetic in any base from two to sixty-four.
Name: A word consisting solely of letters, numbers, and underscores, and beginning with a letter or underscore. Names are used as shell variables and function names. Also referred to as an identifier.
nano hello.sh
#!/bin/bash
echo "Hello World"
./hello-world.shBash Reference Manual
Bash for beginners
Git is an additive version control system used to aid cooperation on projects. It is usually used in conjunction with Github. Git and Github are almost ubiquitiously used by tech companies and is extremely useful to learn. Github is a great place to host your portfolio and demonstrate your knowledge.
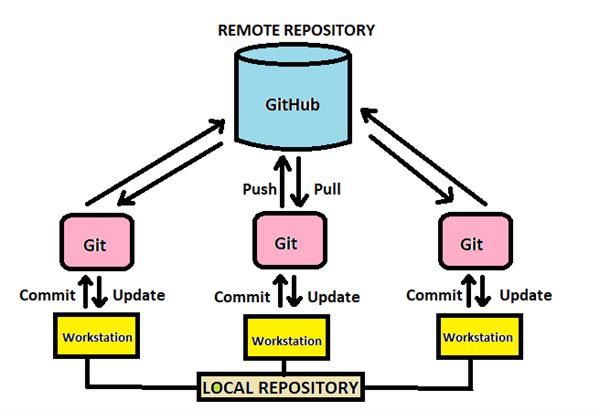
📖 Git book: a really helpful website
Guides to contributing to open source:
Contributing to your first open source project
Blog how to make your first contribution
Hacktoberfest 🎃
Scikitlearn contribution guide
How to write a good commit message 😍
Markdown help: ![]()
Markdown Cheatsheet (general)
Mastering markdown
List of great github profile readmes
List of github actions repos
Emoji Cheatsheet 😍
Simple Icons
Shield Badge Creator 🛡️
Helpful Videos:
My general initial local project workflow:
- git init repo in directory
- git switch -c <branch-name>
- git add files
- git status
- git commit -m "asdf"
- git fetch origin master
- git push -u origin master
🐳 Docker is an open platform for developing, shipping, and running applications. Docker provides the ability to package and run an application in a loosely isolated environment called a container.

Docker architecture
Docker uses a client-server architecture. The Docker client talks to the Docker daemon, which does the heavy lifting of building, running, and distributing your Docker containers. The Docker client and daemon can run on the same system, or you can connect a Docker client to a remote Docker daemon. The Docker client and daemon communicate using a REST API, over UNIX sockets or a network interface. Another Docker client is Docker Compose, which lets you work with applications consisting of a set of containers.
The Docker daemon
The Docker daemon (dockerd) listens for Docker API requests and manages Docker objects such as images, containers, networks, and volumes. A daemon can also communicate with other daemons to manage Docker services.
The Docker client
The Docker client (docker) is the primary way that many Docker users interact with Docker. When you use commands such as docker run, the client sends these commands to dockerd, which carries them out. The docker command uses the Docker API. The Docker client can communicate with more than one daemon.
Docker registries
A Docker registry stores Docker images. Docker Hub is a public registry that anyone can use, and Docker is configured to look for images on Docker Hub by default. You can even run your own private registry.
When you use the docker pull or docker run commands, the required images are pulled from your configured registry. When you use the docker push command, your image is pushed to your configured registry.
Docker objects
When you use Docker, you are creating and using images, containers, networks, volumes, plugins, and other objects.
Images
An image is a read-only template with instructions for creating a Docker container. Often, an image is based on another image, with some additional customization. For example, you may build an image which is based on the ubuntu image, but installs the Apache web server and your application, as well as the configuration details needed to make your application run.
You might create your own images or you might only use those created by others and published in a registry. To build your own image, you create a Dockerfile with a simple syntax for defining the steps needed to create the image and run it. Each instruction in a Dockerfile creates a layer in the image. When you change the Dockerfile and rebuild the image, only those layers which have changed are rebuilt. This is part of what makes images so lightweight, small, and fast, when compared to other virtualization technologies.
Containers
A container is a runnable instance of an image. You can create, start, stop, move, or delete a container using the Docker API or CLI. You can connect a container to one or more networks, attach storage to it, or even create a new image based on its current state.
By default, a container is relatively well isolated from other containers and its host machine. You can control how isolated a container’s network, storage, or other underlying subsystems are from other containers or from the host machine.
A container is defined by its image as well as any configuration options you provide to it when you create or start it. When a container is removed, any changes to its state that are not stored in persistent storage disappear.
Docker Swarm: emphasizes ease of use, making it most suitable for simple applications that are quick to deploy and easy to manage. Manages multiple containers.
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications. Manages multiple containers
A backend JavaScript runtime environment which can execute javaScript outside of a web browser. Node lets you use command line tools and for server-side scripting where dynamic web page content is produced before the page is sent to the user’s browser.
Here is how PHP or ASP handles a file request:
- Sends the task to the computer's file system.
- Waits while the file system opens and reads the file.
- Returns the content to the client.
- Ready to handle the next request.
Here is how Node.js handles a file request:
- Sends the task to the computer's file system.
- Ready to handle the next request.
- When the file system has opened and read the file, the server returns the content to the client.
Node.js eliminates the waiting, and simply continues with the next request.
Node.js runs single-threaded, non-blocking, asynchronous programming, which is very memory efficient.
- Node.js can generate dynamic page content
- Node.js can create, open, read, write, delete, and close files on the server
- Node.js can collect form data
- Node.js can add, delete, modify data in your database
Node interview repo
Node interview questions
![]() React.js is JavaScript Library for building user interfaces
React.js is JavaScript Library for building user interfaces
SQL is a standard querry language for storing, manipulating and retrieving data in databases.
Format of a SQL query:
- SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
- ORDER BY
Example:
SELECT CustomerName, City
FROM Customers
WHERE CustomerName='John Smith';Left join example:
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID
ORDER BY Customers.CustomerName;What are the SQL aggregate functions?
- COUNT
- MAX/MIN
- AVG
- GROUP BY
- CASE
- DISTINCT
- JOINS
What are the different types of joins and can you explain them?
What is a view?
What are entities and relationships?
SQL vs NoSQl:
| SQL | NoSQL |
|---|---|
| vertically scalable | horizontally scalable |
| table based | document, key-value, graph or wide-column stores |
| better for multi-row transactions | better for unstructured data like documents or JSON |
NoSQL is a collection of data items represented in a key-value store, document store, wide column store, or a graph database. Data is denormalized, and joins are generally done in the application code. Most NoSQL stores lack true ACID transactions and favor eventual consistency.
Key-Value Store
Abstraction: hash table
A key-value store generally allows for O(1) reads and writes and is often backed by memory or SSD. Data stores can maintain keys in lexicographic order, allowing efficient retrieval of key ranges. Key-value stores can allow for storing of metadata with a value.
Document Store
Abstraction: key-value store with documents stored as values
A document store is centered around documents (XML, JSON, binary, etc), where a document stores all information for a given object. Document stores provide APIs or a query language to query based on the internal structure of the document itself. Note, many key-value stores include features for working with a value's metadata, blurring the lines between these two storage types.
Wide Column Store
Abstraction: nested map
A wide column store's basic unit of data is a column (name/value pair). A column can be grouped in column families (analogous to a SQL table). Super column families further group column families. You can access each column independently with a row key, and columns with the same row key form a row. Each value contains a timestamp for versioning and for conflict resolution.
Graph Database
Abstraction: graph
In a graph database, each node is a record and each arc is a relationship between two nodes. Graph databases are optimized to represent complex relationships with many foreign keys or many-to-many relationships.
Graphs databases offer high performance for data models with complex relationships, such as a social network
BASE is often used to describe the properties of NoSQL databases. In comparison with the CAP Theorem, BASE chooses availability over consistency.
- Basically available - the system guarantees availability.
- Soft state - the state of the system may change over time, even without input.
- Eventual consistency - the system will become consistent over a period of time, given that the system doesn't receive input during that period.
A database is a collection of related data which represents some aspect of the real world. A database system is designed to be built and populated with data for a certain task.
- Database Management System is a software for storing and retrieving users' data while considering appropriate security measures. It consists of a group of programs which manipulate the database. The DBMS accepts the request for data from an application and instructs the operating system to provide the specific data. In large systems, a DBMS helps users and other third-party software to store and retrieve data.
Database management systems were developed to handle the following difficulties of typical File-processing systems supported by conventional operating systems.
- Data redundancy and inconsistency
- Difficulty in accessing data
- Data isolation – multiple files and formats
- Integrity problems
- Atomicity of updates
- Concurrent access by multiple users
- Security problems
- DDL is short for Data Definition Language, which deals with database schemas and descriptions, of how the data should reside in the database.
- CREATE
- to create a database and its objects like (table, index, views, store procedure, function, and triggers)
- ALTER
- alters the structure of the existing database
- DROP
- delete objects from the database
- TRUNCATE
- remove all records from a table, including all spaces allocated for the records are removed
- RENAME
- rename an object
- CREATE
- DML is short for Data Manipulation Language which deals with data manipulation and includes most common SQL statements such SELECT, INSERT, UPDATE, DELETE, etc., and it is used to store, modify, retrieve, delete and update data in a database.
- SELECT
- retrieve data from a database
- INSERT
- insert data into a table
- UPDATE
- updates existing data within a table
- DELETE
- Delete all records from a database table
- MERGE
- UPSERT operation (insert or update)
- SELECT
- DCL is short for Data Control Language and is mostly concerned with rights, permissions and other controls of the database system.
- GRANT
- allow users access privileges to the database
- REVOKE
- withdraw users access privileges given by using the GRANT command
- GRANT
- TCL is short for Transaction Control Language which deals with a transaction within a database.
- COMMIT
- commits a Transaction
- ROLLBACK
- rollback a transaction in case of any error occurs ● SAVEPOINT - to roll back the transaction making points within groups
- COMMIT
-
ER diagram or Entity Relationship diagram is a conceptual model that gives the graphical representation of the logical structure of the database.
-
It shows all the constraints and relationships that exist among the different components.
-
An ER diagram is mainly composed of following three components- Entity Sets, Attributes and Relationship Set.
-
Roll_no is a primary key that can identify each entity uniquely.
-
Thus, by using a student's roll number, a student can be identified uniquely.
An entity set is a set of the same type of entities.
- Strong Entity Set:
- A strong entity set is an entity set that contains sufficient attributes to uniquely identify all its entities.
- In other words, a primary key exists for a strong entity set.
- Primary key of a strong entity set is represented by underlining it.
- Weak Entity Set:
- A weak entity set is an entity set that does not contain sufficient attributes to uniquely identify its entities.
- In other words, a primary key does not exist for a weak entity set.
- However, it contains a partial key called a discriminator.
- Discriminator can identify a group of entities from the entity set.
- Discriminator is represented by underlining with a dashed line.
A relationship is defined as an association among several entities.
- Unary Relationship Set -
- Unary relationship set is a relationship set where only one entity set participates in a relationship set.
- Binary Relationship Set -
- Binary relationship set is a relationship set where two entity sets participate in a relationship set.
- Ternary Relationship Set -
- Ternary relationship set is a relationship set where three entity sets participate in a relationship set.
- N-ary Relationship Set -
- N-ary relationship set is a relationship set where ‘n’ entity sets participate in a relationship set.
Attributes are the descriptive properties which are owned by each entity of an Entity Set.
- Types of Attributes:
- Simple Attributes -
- Simple attributes are those attributes which cannot be divided further. Ex. Age
- Composite Attributes -
- Composite attributes are those attributes which are composed of many other simple attributes. Ex. Name, Address
- Multi Valued Attributes -
- Multi valued attributes are those attributes which can take more than one value for a given entity from an entity set. Ex. Mobile No, Email ID
- Derived Attributes -
- Derived attributes are those attributes which can be derived from other attribute(s). Ex. Age can be derived from DOB.
- Key Attributes -
- Key attributes are those attributes which can identify an entity uniquely in an entity set. Ex. Roll No.
- Simple Attributes -
- The set of all those attributes which can be functionally determined from an attribute set is called a closure of that attribute set
- Relational constraints are the restrictions imposed on the database contents and operations. They ensure the correctness of data in the database.
- Domain Constraint -
- Domain constraint defines the domain or set of values for an attribute. It specifies that the value taken by the attribute must be the atomic value from its domain.
- Tuple Uniqueness Constraint -
- Tuple Uniqueness constraint specifies that all the tuples must be necessarily unique in any relation.
- Key Constraint -
- All the values of the primary key must be unique. The value of the primary key must not be null.
- Entity Integrity Constraint -
- Entity integrity constraint specifies that no attribute of primary key must contain a null value in any relation.
- Referential Integrity Constraint -
- It specifies that all the values taken by the foreign key must either be available in the relation of the primary key or be null.
- Domain Constraint -
Primary Key (PK):
A column with a unique value for each row.
Although not all database management systems (DBMS) require you to put a PK into each table, from a design perspective a PK is a requirement. No table should be without one.
Foreign Key (FK):
These define relationships between tables. When you want a row in one table to be linked to a row in another table, you place a FK column in the child table and use the value of the parent row's PK as the value of the FK field.
Composite Key:
This is a key that is made up of more than one column.
This is typically used when you want to prevent a table from using the same combination of values twice. For example, in a table that lists item prizes for shops, you would only want each shop to have a single price for each item. So, you create a FK for the shop and a FK for the item, and then you create a composite PK out of those two columns. This would cause the DBMS to forcefully restrict entries that would create rows where the combined values of these fields are duplicated. - This type of key is commonly used in N:M relationships.
One-To-One (1:1) relationship:
A relationship between two tables, where a single row in one table is linked to a single row in another table.
This type of relationship is practically non-existent in normalized relational designs. They exist mostly to get around limitations in databases like Access, where the number of columns was limited, thus creating the need to split tables up. They are also sometimes used to optimize the performance of the database.
One-To-Many (1:N) relationship:
A relationship between two tables, where multiple rows in a child table can be linked to a single row in a parent table.
This is in fact the only "real" type of relationship in a relational database.
Many-To-Many (N:M) relationship:
A relationship between two tables, where multiple rows in one table can be linked to multiple rows in another table.
This type is "artificial" in a a way, because this kind of relationship can not be created directly between tables. To accomplish this type of relationship you need to create a third table; an intermediary table that contains FKs to both parents, linked via a set of 1:N relationships.
To help us properly design our tables we have a set of guidelines which, if followed properly, will help reduce the redundancy and chance of data corruption. We call this "Normalization".
Database Design and Normalization
Another Database Normalization walkthrough
There are several steps involved in normalizing a database. The steps are referred to as "Normal Forms". There are at least 7 NF. Each NF requires that the NF before it has also been satisfied. The spot between 3NF and 4NF is reserved for the BCNF (Boyce-Codd normal form), which was developed later as a slightly stronger version of the 3NF. Tables that have reached the 3NF are generally considered "normalized".
- 1NF: tables must not contain repeating groups of data
- 2NF: no field should only be partially dependent on any candidate key
- 3NF: columns should depend only upon the primary key of the table
Denormalization is the process of improving the read speed in a database at the expense of write performance, by adding redundant copies of data and by grouping.
When to Denormalize
- Transaction is a single logical unit of work formed by a set of operations.
Operations in Transaction:
- Read Operation -
- Read(A) instruction will read the value of ‘A’ from the database and will store it in the buffer in main memory.
- Write Operation –
- Write(A) will write the updated value of ‘A’ from the buffer to the database.
Transaction States:
-
Active State –
- This is the first state in the life cycle of a transaction.
- A transaction is called in an active state as long as its instructions are getting executed.
- All the changes made by the transaction now are stored in the buffer in main memory.
-
Partially Committed State –
- After the last instruction of the transaction has been executed, it enters into a partially committed state.
- It is not considered fully committed because all the changes made by the transaction are still stored in the buffer in main memory.
-
Committed State –
- After all the changes made by the transaction have been successfully stored into the database, it enters into a committed state.
-
Failed State –
- When a transaction is getting executed in the active state or partially committed state and some failure occurs due to which it becomes impossible to continue the execution, it enters into a failed state.
-
Aborted State –
- After the transaction has failed and entered into a failed state, all the changes made by it have to be undone.
- To undo the changes made by the transaction, it becomes necessary to roll back the transaction.
- After the transaction has rolled back completely, it enters into an aborted state.
-
Terminated State –
- After entering the committed state or aborted state, the transaction finally enters into a terminated state where its life cycle finally comes to an end.
- Primary Index:
- A primary index is an ordered file, records of fixed length with two fields. First field is the same as the primary key as a data file and the second field is a pointer to the data block, where the key is available. The average number of block accesses using index = log2 Bi + 1, where Bi = number of index blocks.
- Clustering Index:
- Clustering index is created on data file whose records are physically ordered on a non-key field (called Clustering field).
- Secondary Index:
- Secondary index provides secondary means of accessing a file for which primary access already exists.
B-Tree
A self balancing tree used as a database
- At every level , we have Key and Data Pointer and data pointer points to either block or record.
Properties of B-Trees:
- Root of B-tree can have children between 2 and P, where P is Order of tree.
- Order of tree – Maximum number of children a node can have.
- Internal node can have children between ⌈ P/2 ⌉ and P
- Internal node can have keys between ⌈ P/2 ⌉ – 1 and P-1
Extract Transform Load is the procedure for copying data into a different system. We do this to gather and clean data and transfer the data into an easily stored and queryable form.
Databricks ETL
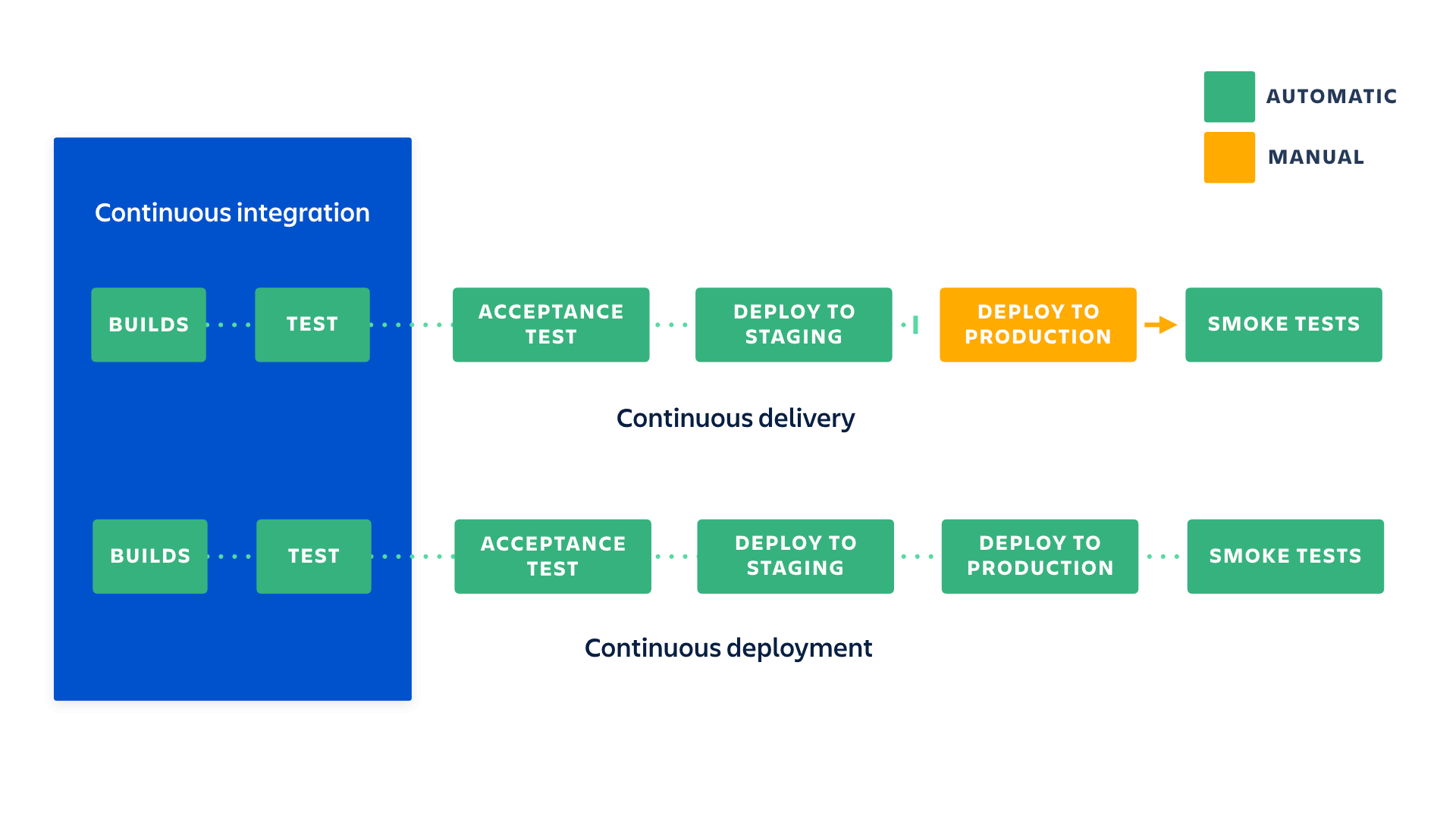
🚀 CI and CD are two acronyms frequently used in modern development practices and DevOps. CI stands for continuous integration, a fundamental DevOps best practice where developers frequently merge code changes into a central repository where automated builds and tests run. But CD can either mean continuous delivery or continuous deployment.
Redhat what is ci/cd
Atlassian ci vs cd
RESTful API:
- An architectural style for an application program interface (API) that uses HTTP requests to access and use data. That data can be used to GET, PUT, POST and DELETE data types, which refers to the reading, updating, creating and deleting of operations concerning resources.
REST = REpresentational State Transfer
CRUD : for persistent data
-
Create = post
-
Read = get
-
Update = put
-
Delete = delete
-
GET to retrieve a resource;
-
PUT to change the state of or update a resource, which can be an object, file or block;
-
POST to create that resource; and
-
DELETE to remove it.
Persistence is said to be "orthogonal" or "transparent" when it is implemented as an intrinsic property of the execution environment of a program. An orthogonal persistence environment does not require any specific actions by programs running in it to retrieve or save their state.
Non-orthogonal persistence requires data to be written and read to and from storage using specific instructions in a program, resulting in the use of persist as a transitive verb: On completion, the program persists the data. The advantage of orthogonal persistence environments is simpler and less error-prone programs
SOAP (formerly an acronym for Simple Object Access Protocol) is a messaging protocol specification for exchanging structured information in the implementation of web services in computer networks. It uses XML Information Set for its message format, and relies on application layer protocols, most often Hypertext Transfer Protocol (HTTP)
GraphQL:
- A query/manipulation language for your API and a runtime for fulfilling queries with existing data
- https://graphql.guide/
OLTP vs OLAP
- link
- Both are online processing systems. OLTP is a transactional processing sys which modifies data while OLAP is an analytical processing system which queries.
(Hypertext Transfer Protocol)
(HTTP) is an application-layer protocol for transmitting hypermedia documents, such as HTML. It was designed for communication between web browsers and web servers, but it can also be used for other purposes. HTTP follows a classical client-server model, with a client opening a connection to make a request, then waiting until it receives a response. HTTP is a stateless protocol, meaning that the server does not keep any data (state) between two requests. Though often based on a TCP/IP layer, it can be used on any reliable transport layer, that is, a protocol that doesn't lose messages silently like UDP does. RUDP — the reliable update of UDP — is a suitable alternative.
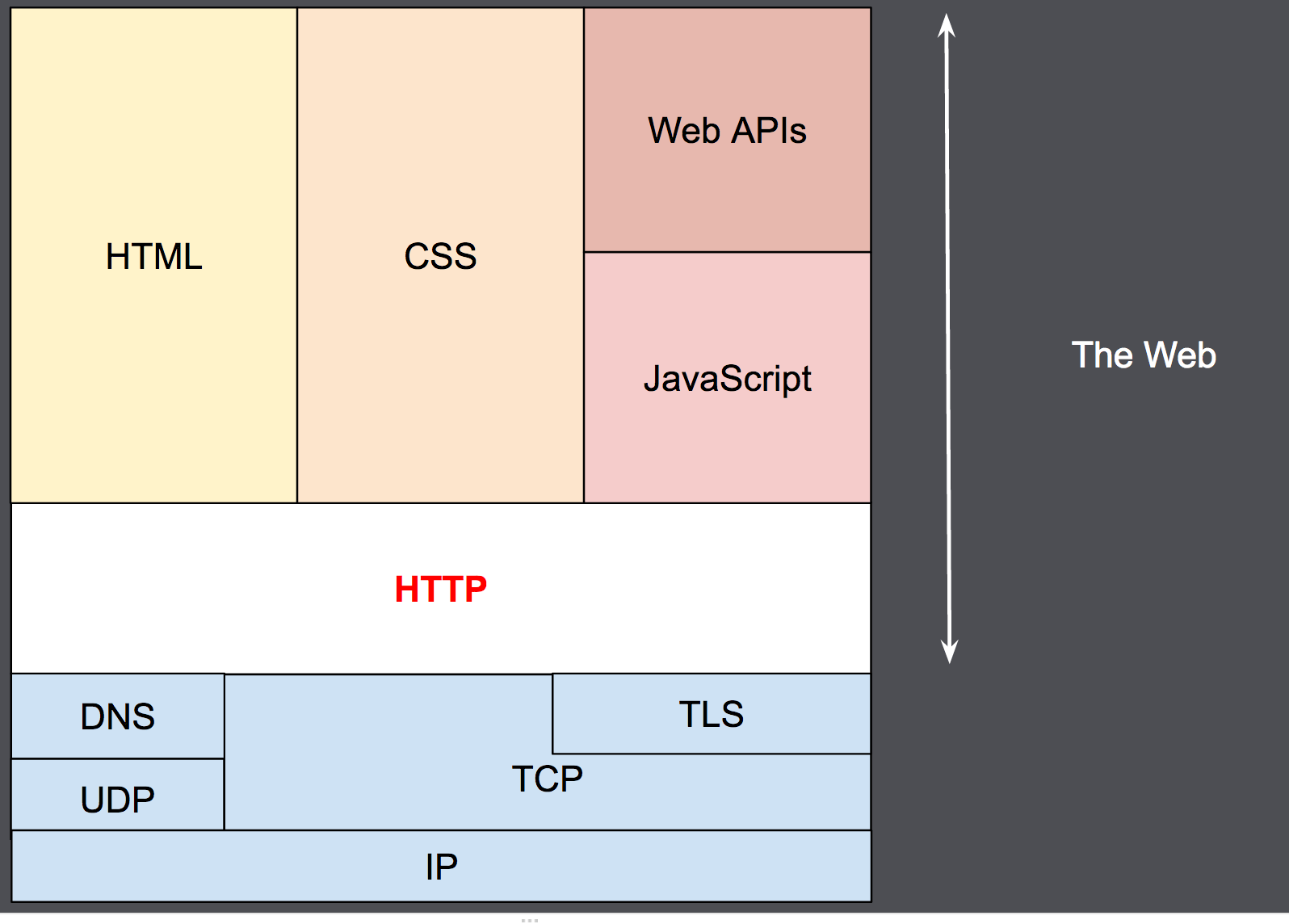

Caching: https://developer.mozilla.org/en-US/docs/Web/HTTP/Caching
Cookies: 🍪
- a small piece of data that a server sends to the user's web browser. The browser may store it and send it back with later requests to the same server. Typically, it's used to tell if two requests came from the same browser — keeping a user logged-in, for example. It remembers stateful information for the stateless HTTP protocol.
Cookies are mainly used for three purposes:
- Session management
- Logins, shopping carts, game scores, or anything else the server should remember
- Personalization
- User preferences, themes, and other settings
- Tracking
- Recording and analyzing user behavior
Indicate the desired action to be performed for a given resource. Each of them implements a different semantic, but some common features are shared by a group of them: e.g. a request method can be safe, idempotent, or cacheable.
- GET
- The GET method requests a representation of the specified resource. Requests using GET should only retrieve data.
- HEAD
- The HEAD method asks for a response identical to that of a GET request, but without the response body.
- POST
- The POST method is used to submit an entity to the specified resource, often causing a change in state or side effects on the server.
- PUT
- The PUT method replaces all current representations of the target resource with the request payload.
- DELETE
- The DELETE method deletes the specified resource.
- CONNECT
- The CONNECT method establishes a tunnel to the server identified by the target resource.
- OPTIONS
- The OPTIONS method is used to describe the communication options for the target resource.
- TRACE
- The TRACE method performs a message loop-back test along the path to the target resource.
- PATCH
- The PATCH method is used to apply partial modifications to a resource.
WebSockets:
- Provide a persistent connection between a client and server that both parties can use to start sending data at any time.
https://blog.teamtreehouse.com/an-introduction-to-websockets
The client establishes a WebSocket connection through a process known as the WebSocket handshake. This process starts with the client sending a regular HTTP request to the server. An Upgrade header is included in this request that informs the server that the client wishes to establish a WebSocket connection.
Here is a simplified example of the initial request headers.
- GET ws://websocket.example.com/ HTTP/1.1
- Origin: http://example.com
- Connection: Upgrade
- Host: websocket.example.com
- Upgrade: websocket
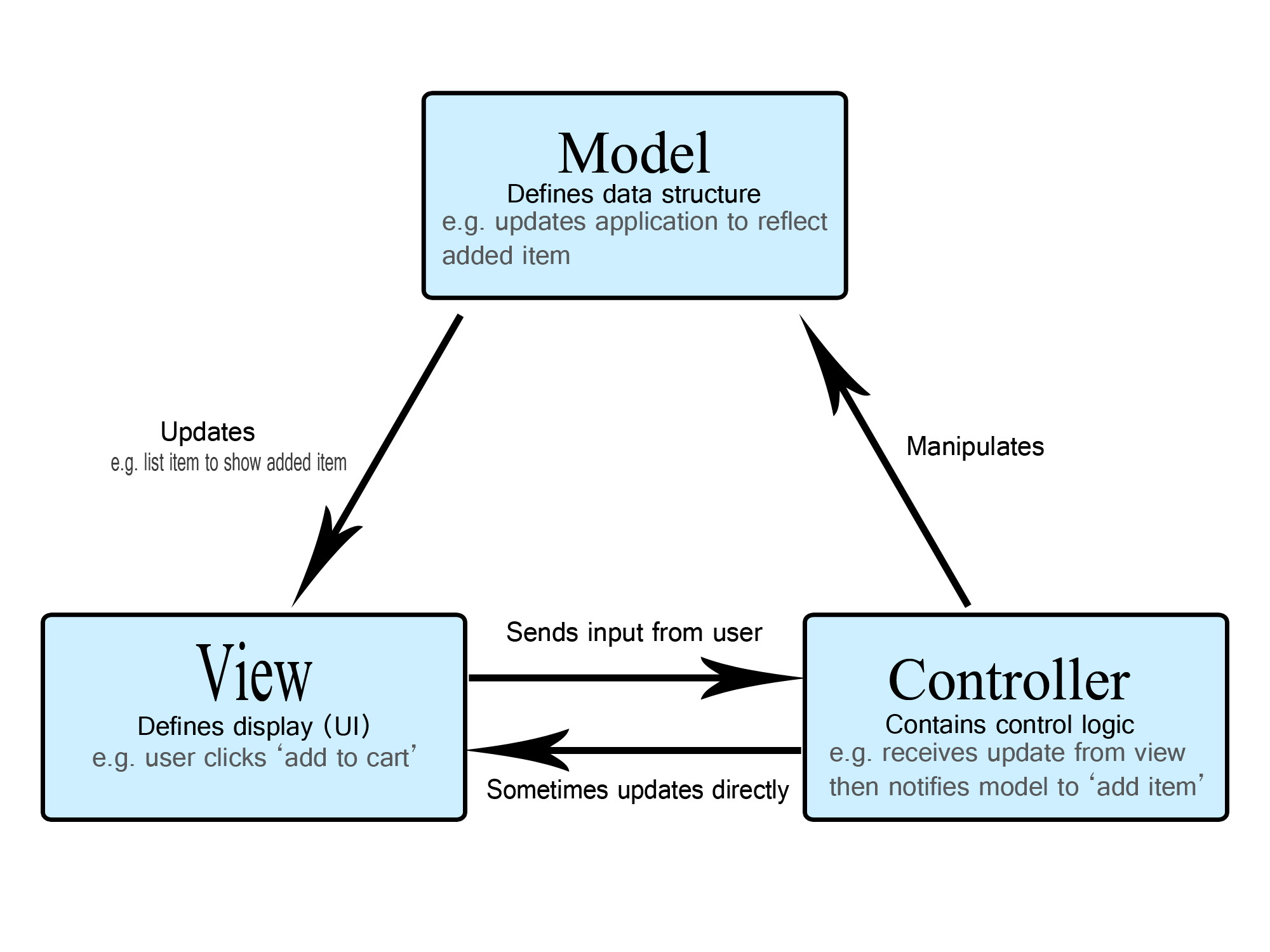
- Model
- The central component of the pattern. It is the application's dynamic data structure, independent of the user interface. It directly manages the data, logic and rules of the application. It receives user input from the controller.
- View
- Any representation of information such as a chart, diagram or table.
- Controller
- Accepts input and converts it to commands for the model or view
☁️ I took the AWS cloud practioner ceritification and passed after two days of studying mainly using resources provided by AWS. This is the easiest AWS certification, but there are a lot of general pieces of knowledge needed to pass it.
What the Cloud is: servers that are accessed over the internet, and the software and databases that run on those servers.
Serverless: an AWS architectural design principle based, where developers focus on the applications that they want to put into AWS resources, and serverless solutions such as AWS Lambda will then interpret the application and provision the compute and storage power required for execution.
Virtual Private Cloud (VPC):
a plot of virtual space within the Amazon Cloud to work within. A user or account may have many VPCs, but must have at least one VPC to act as a designated workspace to house your AWS cloud resources. VPC is a backbone principle of AWS cloud architecture, and they can connect to one another to create private and public networks.
VPC has 4 main subcomponents
- SUBNET: a network inside an IP network.
- INTERNET GATEWAY: connection between your VPC and the internet
- ROUTE TABLE: contains a set of rules, called routes, that are used to determine where network traffic from your subnet or gateway is directed.
- NETWORK ACCESS CONTROL LIST (NACL)
Elastic Compute Cloud (EC2): a scalable computing capacity or virtual machine (VM) powered by AWS. A backbone resource of AWS that supports application hosting, remote network logins and gateways, database hosting and more.
Simple Storage Service (S3): has a simple web services interface that you can use to store and retrieve any amount of data, at any time, from anywhere on the web. This data is stored in buckets, and you pay as you go for the size of storage you need. S3 is not able to be queried like a database and is not designed for frequent or mass request access. S3 buckets can be used to house the files such as HTML, JS, and CSS for a static web site, and then host that static website.
Relational Database Service (RDS): RDS makes it easy to set up, operate, and scale a relational database in the cloud. It provides cost-efficient and resizable capacity while automating time-consuming administration tasks such as hardware provisioning, database setup, patching and backups. It frees you to focus on your applications so you can give them the fast performance, high availability, security and compatibility they need. Amazon RDS is available on several database instance types - optimized for memory, performance or I/O - and provides you with six database engines to choose from, including Aurora, PostgreSQL, MySQL, MariaDB, Oracle Database, and SQL Server.
Elastic Block Store (EBS): is a block-storage service designed for use with Amazon Elastic Compute Cloud (EC2) for both throughput and transaction intensive workloads at scale. A broad range of workloads, such as relational and non-relational databases, enterprise applications, containerized applications, big data analytics engines, file systems, and media workflows are deployed on Amazon EBS. You may only mount one EC2 to an EBS at a time. Designed for mission-critical systems, EBS volumes are replicated within an Availability Zone (AZ) and can easily scale to petabytes of data. Also, you can use EBS Snapshots with automated lifecycle policies to back up your volumes in S3, while ensuring geographic protection of your data and business continuity.
Elastic File System (EFS): a network file system (NFS), that is scalable and fully managed by AWS. Amazon EFS is designed to provide massively parallel shared access to thousands of Amazon EC2 instances. Customers can use EFS to lift-and-shift existing enterprise applications to the AWS Cloud. Other use cases: big data analytics, web serving and content management, application development and testing, media workflows, database backups, and container storage. EFS is a regional service storing data within and across multiple (AZs) for high availability and durability. Amazon EC2 instances can access your file system across AZs, regions, and VPCs, while on-premises servers can access using AWS Direct Connect or AWS VPN. Not supported for Windows EC2 Instances.
FSx: see above EFS. Comparable to EFS but built on Windows Server and supports Windows EC2, Linux, and MacOS Compute Instances.
Identity and Access Management (IAM): AWS Identity and Access Management (IAM) enables you to manage access to AWS services and resources securely. Using IAM, you can create and manage AWS users and groups, and use permissions.
AWS Lambda: is a serverless compute service that lets you run code without provisioning ormanaging servers, creating workload-aware cluster scaling logic, maintaining event integrations, or managing runtimes. Just upload your code as a ZIP file or container image, and Lambda allocates compute execution power and runs your code based on the incoming request or event. You can set up your code to automatically trigger from 140 AWS services or call it directly. You can write Lambda functions in any language and use both serverless and container tools, such as AWS SAM or Docker CLI, to build, test, and deploy your Functions.
Amazon SageMaker: is a fully-managed service that enables data scientists and developers to quickly build, train, and deploy machine learning models at any scale.
| NACL | Security Group |
|---|---|
| NACL can be understood as the firewall for the subnet | Security group can be understood as a firewall to protect EC2 instances |
| Stateless, meaning any change applied to an incoming rule isn’t automatically applied to an outgoing rule | Stateful, any changes which are applied to an incoming rule is automatically applied to an outgoing rule |
What are the different types of EC2 instances?
There 5 different types of EC2 instances: general purpose, compute-optimized, memory-optimized, storage-optimized, accelerated computing. Know each.
IaaS: Infastructure as a Service -using virtual resources
PaaS: Platform as a Service -a platform for an end user to manage applications
SaaS: Software as a Service -on demand software
FaaS: Function as a Service -manage functions
DaaS: Data as a Service
What are the 5 pillars of the AWS framework?
- Operational Excellence
- Security
- Reliability
- Performance Efficiency
- Cost Optimization
Can you explain the concept of serverless?
🛠️ There are many approaches available in software testing. Reviews, walkthroughs, or inspections are referred to as static testing(verification), whereas executing programmed code with a given set of test cases is referred to as dynamic testing(validation)
Automation Testing: Selenium and Katalon Studio
an internal perspective of the system, as well as programming skills, are used to design test cases. This testing is usually done at the unit level.
- API testing: testing of the application using public and private APIs (application programming interfaces)
- Code coverage: creating tests to satisfy some criteria of code coverage (e.g., the test designer can create tests to cause all statements in the program to be executed at least once)
- Fault injection methods: intentionally introducing faults to gauge the efficacy of testing strategies
- Mutation testing methods
- Static testing methods
testing method in which testers evaluate the functionality of the software under test without looking at the internal code structure.
- Black-box testing methods include: equivalence partitioning, boundary value analysis, all-pairs testing, state transition tables, decision table testing, fuzz testing, model-based testing, use case testing, exploratory testing, and specification-based testing. It can be applied to all levels of software testing, usually used at higher levels.
involves having knowledge of internal data structures and algorithms for purposes of designing tests while executing those tests at the user, or black-box level.
1. Unit Testing - Unit testing refers to tests that verify the functionality of a specific section of code, usually at the function level. In an object-oriented environment, this is usually at the class level, and the minimal unit tests include the constructors and destructors. - Unit testing might include static code analysis, data-flow analysis, metrics analysis, peer code reviews, code coverage analysis and other software testing practices.
2. Integration Testing:
Integration Testing is the process of testing the connectivity or data transfer between a couple of unit tested modules.
3. System Testing:
A completely integrated system to verify that the system meets its requirements. For example, a system test might involve testing a login interface, then creating and editing an entry, plus sending or printing results, followed by summary processing or deletion (or archiving) of entries, then logoff.
4. Acceptance Testing:
Operational readiness of the system to be supported and integrated. Final Step to see if it doesn’t break anything else.
Installation testing: self explanatory
Compatibility testing: Testing compatibility with other applications or OS or versions.
Smoke and Sanity testing:
- Sanity testing determines whether or not to test further
- Smoke testing consists of minimal attempts to operate the software
Regression testing: Method for finding defects after a major code change. To find regressions (degraded or lost features).
Acceptance testing: A smoke test or acceptance testing by the customer.
Alpha/beta testing: user acceptance testing by the customer/ testers
Functional vs non-functional testing: test if it fits specifications vs performance and scalability
Continuous testing: using automated tests as part of the delivery pipeline
Destructive testing: attempts to cause the software to fail
Talk to me about which debuggers/testing software you have used in order to fix programming errors?
Test Driven Development: (develop tests before coding)
Multiple processes done in separate memory locations
Both processes and threads are independent sequences of execution. The typical difference is that threads (of the same process) run in a shared memory space, while processes run in separate memory spaces.
- A Fork is when a process creates a copy of itself.
Each process provides the resources needed to execute a program. A process has a virtual address space, executable code, open handles to system objects, a security context, a unique process identifier, environment variables, a priority class, minimum and maximum working set sizes, and at least one thread of execution. Each process is started with a single thread, often called the primary thread, but can create additional threads from any of its threads.
🧵 A thread is an entity within a process that can be scheduled for execution. All threads of a process share its virtual address space and system resources. In addition, each thread maintains exception handlers, a scheduling priority, thread local storage, a unique thread identifier, and a set of structures the system will use to save the thread context until it is scheduled. The thread context includes the thread's set of machine registers, the kernel stack, a thread environment block, and a user stack in the address space of the thread's process. Threads can also have their own security context, which can be used for impersonating clients.
Concurrency: https://en.wikipedia.org/wiki/Concurrency_(computer_science)
Daemon: https://en.wikipedia.org/wiki/Daemon_(computing)
- Async makes a function return a Promise
- Await makes a function wait for a Promise Fake synchronous checks if we are not breaking the execution thread
A Promise is a proxy for a value not necessarily known when the promise is created. It allows you to associate handlers with an asynchronous action's eventual success value or failure reason. This lets asynchronous methods return values like synchronous methods: instead of immediately returning the final value, the asynchronous method returns a promise to supply the value at some point in the future.
A Promise is in one of these states:
- Pending: initial state, neither fulfilled nor rejected.
- Fulfilled: meaning that the operation was completed successfully.
- Rejected: meaning that the operation failed.
Consider the standard producer-consumer problem. Assume, we have a buffer of 4096-byte length. A producer thread collects the data and writes it to the buffer. A consumer thread processes the collected data from the buffer. The objective is, both the threads should not run at the same time.
A mutex is a locking mechanism used to synchronize access to a resource. Only one task (can be a thread or process based on OS abstraction) can acquire the mutex. It means there is ownership associated with a mutex, and only the owner can release the lock (mutex).
Using Mutex:
- A mutex provides mutual exclusion, either producer or consumer can have the key (mutex) and proceed with their work. As long as the buffer is filled by the producer, the consumer needs to wait, and vice versa.
- At any point of time, only one thread can work with the entire buffer. The concept can be generalized using semaphore.
🎌 Semaphore is a signaling mechanism (“I am done, you can carry on” kind of signal). For example, if you are listening to songs (assume it as one task) on your mobile phone and at the same time, your friend calls you, an interrupt is triggered upon which an interrupt service routine (ISR) signals the call processing task to wake up.
Using Semaphore:
- A semaphore is a generalized mutex. In lieu of a single buffer, we can split the 4 KB buffer into four 1 KB buffers (identical resources). A semaphore can be associated with these four buffers. The consumer and producer can work on different buffers at the same time.
🏗️ This section is more of a high level view of some important things to know about database design and software design. You may get a more in depth system design focused interview where you are asked to design a product or fix/improve one.
Here is a useful repo for a system design interview
- Atomicity - each transaction is a single unit (fails or succeeds completely)
- Consistency - a transaction can only bring the database from one valid state to another
- Isolation - all transactions in a concurrent stream get executed fully
- Durability - once a transaction has been committed it will remain so
this states that it is not possible for a distributed computer system to simultaneously provide all three of the following guarantees:
- Consistency (all nodes see the same data even at the same time with concurrent updates )
- Availability (a guarantee that every request receives a response about whether it was successful or failed)
- Partition tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)
Candidate design features for software reuse include:
- Adaptable
- Brief: small size
- Consistency
- Correctness
- Extensibility
- Fast
- Flexible
- Generic
- Localization of volatile (changeable) design assumptions (David Parnas)
- Modularity
- Orthogonality
- Parameterization
- Simple: low complexity
- Stability under changing requirements
Five design principles intended to make software designs more understandable, flexible, and maintainable
This principle states that there should never be more than one reason for a class to change. This means that you should design your classes in such a way that each class should have a single purpose.
- Ex: An Account class is responsible for managing Current and Saving Account but a CurAccount and a SavingAccount classes are specialized. Hence both are responsible for a single purpose only.
This principle states that software entities (classes, modules, functions, etc.) should be open for extension but closed for modification. The "closed" part of the rule states that once a module has been developed and tested, the code should only be changed to correct bugs. The "open" part says that you should be able to extend existing code in order to introduce new functionality.
- Ex: A PaymentGateway base class contains all basic payment related properties and methods. This class can be extended by different PaymentGateway classes for different payment gateway vendors to achieve their functionalities. Hence it is open for extension but closed for modification.
This principle states that functions that use pointers or references to base classes must be able to use objects of derived classes without knowing it.
- Ex: Assume that you have an inheritance hierarchy with Person and Student. Wherever you can use Person, you should also be able to use a Student, because Student is a subclass of Person.
This principle states that Clients should not be forced to depend upon interfaces that they don’t use. This means the number of members in the interface that is visible to the dependent class should be minimized.
- High level modules should not depend upon low level modules. Both should depend upon abstractions.
- Abstractions should not depend upon details. Details should depend upon abstractions.
- It helps us to develop loosely coupled code by ensuring that high-level modules depend on abstractions rather than concrete implementations of lower-level modules. The Dependency Injection pattern is an implementation of this principle
This principle states that each small piece of knowledge (code) may only occur exactly once in the entire system. This helps us to write scalable, maintainable and reusable code.
https://www.khanacademy.org/math/statistics-probability
Permutations:
Abc, bca, bac, cav, cba, acbb = 3! => n! PEPPER = 6! / (3!2!) n!/(n1!)
Combinations: n choose r
(n r) for r<=n => n! / ((n-r)!r!)
Binomial Theorem
De Morgan’s Laws:
(E U F)^c = E^cF^c (EF)^c = E^c U Fc
Probability: P(E) = (num of outcomes in E) / (num of outcomes in S)
Conditional Probability:
P(E|F) = probability E occurs given F
What is Bayes theorem?
P(A|B) = P(A) P(B|A) / P(B)
Bayes Theorem:
Bayes theorem, the geometry of changing beliefs (video)
A visual guide to Bayesian thinking (video)
What is the diff between precision/specificity?
What is a p-value?
Quantile: value under which a certain percent lies
Dispersion -> Variance: average of the squared deviation from the mean (subtract the mean and square the result, then find the average of those differences)
Standard deviation = variance
How to Learn Statistics for Data Science As A Self Starter (video)
How to Learn Probability Distributions (video)
Probability Density Function (PDF) := the probability of seeing a value in a certain interval equals the integral of the density function over the interval
Cumulative Distribution Function (CDF) := the probability that a random variable is <= a value
Normal distribution: A continuous probability distribution that is symmetric about the mean (Bell curve).
Variance = how scattered the predictions are from the actual value High variance means overfitting
Correlation measures how strongly two variables are related.
- In covariance two items vary together and it’s a measure that indicates the extent to which two random variables change in tandem
Error = bias + variance
Bias = how far the predicted values are from the actual values
High bias means you are underfitting
📚 Python Data Science Handbook
Linkedin Data Analytics help
Univariate analysis is the simplest and easiest form of data analysis where the data being analyzed contains only one variable.
- Example: Studying the heights of players in the NBA.
- Univariate analysis can be described using Central Tendency, Dispersion, Quartiles, Bar charts, Histograms, Pie charts, and Frequency distribution tables.
Bivariate analysis involves the analysis of two variables to find causes, relationships, and correlations between the variables.
- Example: Analyzing the sale of ice creams based on the temperature outside.
- The bivariate analysis can be explained using Correlation coefficients, Linear regression, Logistic regression, Scatter plots, and Box plots.
Multivariate analysis involves the analysis of three or more variables to understand the relationship of each variable with the other variables.
- Example: Analysing Revenue based on expenditure.
- Multivariate analysis can be performed using Multiple regression, Factor analysis, Classification & regression trees, Cluster analysis, Principal component analysis, Dual-axis charts, etc.
a hypothesis that is testable on the basis of observed data modelled as the realised values taken by a collection of random variables. A set of data is modelled as being realised values of a collection of random variables having a joint probability distribution in some set of possible joint distributions. The hypothesis being tested is exactly that set of possible probability distributions.
A statistical hypothesis test is a method of statistical inference. An alternative hypothesis is proposed for the probability distribution of the data, either explicitly or only informally. The comparison of the two models is deemed statistically significant if, according to a threshold probability—the significance level—the data would be unlikely to occur if the null hypothesis were true. A hypothesis test specifies which outcomes of a study may lead to a rejection of the null hypothesis at a pre-specified level of significance, while using a pre-chosen measure of deviation from that hypothesis (the test statistic, or goodness-of-fit measure). The pre-chosen level of significance is the maximal allowed "false positive rate". One wants to control the risk of incorrectly rejecting a true null hypothesis.
A/B testing (also known as split testing or bucket testing) is a method of comparing two versions of a webpage or app against each other to determine which one performs better. AB testing is essentially an experiment where two or more variants of a page are shown to users at random, and statistical analysis is used to determine which variation performs better for a given conversion goal.
- Airbnb experiments and A/B testing
- When Should A/B testing not be trusted
- 12 Guidelines for A/B testing
- A/B testing interview questions
- Pinterests metrics to create growth
How can you handle missing values in a dataset?
- Listwise Deletion
- In the listwise deletion method, an entire record is excluded from analysis if any single value is missing.
- Average Imputation
- Take the average value of the other participants' responses and fill in the missing value.
- Regression Substitution
- You can use multiple-regression analyses to estimate a missing value.
- Multiple Imputations
- It creates plausible values based on the correlations for the missing data and then averages the simulated datasets by incorporating random errors in your predictions.
How do you deal with outliers in a dataset?
- Trim them out ✂️
- Normalize them (log+1) ⛰️
Field Level Validation – In this method, data validation is done in each field as and when a user enters the data. It helps to correct the errors as you go.
Form Level Validation – In this method, the data is validated after the user completes the form and submits it. It checks the entire data entry form at once, validates all the fields in it, and highlights the errors (if any) so that the user can correct it.
Data Saving Validation – This data validation technique is used during the process of saving an actual file or database record. Usually, it is done when multiple data entry forms must be validated.
Search Criteria Validation – This validation technique is used to offer the user accurate and related matches for their searched keywords or phrases. The main purpose of this validation method is to ensure that the user’s search queries can return the most relevant results.
Apache Spark is an open-source unified analytics engine for large-scale data processing. Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance.

🗺️ An ML roadmap
Google ML crash course
Fast AI deep learning course
📚 AIMA online book
Possible Interview Topics:
Statistical distributions
Probability simulation
String parsing and data manipulation
Numpy functions and matrices
Pandas data munging
A project walkthrough
51 Essential Machine Learning Questions
100+ Data Science Interview Questions Edureka
- Classification
- Accuracy
- Precision
- Recall
- Confusion matrix
- F1 score
- Mean average precision (MAP) - object detection
- Jaccard index
- Regression
- RMSE / RMSECV
- MAE
- R^2
- Recall is the true positive rate (pos claims vs actual num of pos)- rate of fish caught in pond
- Precision is the positive predictive value - rate of correct predictions
F1 Score:
A weighted average of the precision and recall of a model (1 best, 0 worst)
- Linear Regression
- Logistic Regression
- k-Nearest Neighbors
- Support Vector Machines (SVM)
- Decision Trees and Random Forest
- AdaBoost and Gradient boosting
- XGBoost
- CatBoost
- LightGBM
- Neural Networks
- Convolutional
- Recurrent (RNN)
- Transformer
- Clustering (K-Means)
- Visualization and dimensionality reduction
- PCA
- Autoencoders
- t-Distributed Stochastic Neighbor Embedding(t-SNE)
- Anomaly Detection
- Autoencoder
- One-class classification
What is the difference between supervised vs unsupervised machine learning?
What is the difference between discriminative and generative models?
- Discriminative
- Learn decision boundaries (ex: svm, regressions)
- Generative
- Learn distributions (ex: naive bayes)
Time series: K-fold cv
Variance = how scattered the predictions are from the actual value
High variance means overfitting
Correlation measures how strongly two variables are related.
In covariance two items vary together and it’s a measure that indicates the extent to which two random variables change in cycle
Error = bias + variance
Bias = how far the predicted values are from the actual values
High bias means you are underfitting
How to deal with underfitting:
- Add features
- Decrease regularization term
How to deal with overfitting: - Reduce number of features
- Increase regularization term
- Dropout- randomly remove parts of your model
- Data Augmentation
- Batch normalization
Regularization is a technique where we penalize the loss function for flexibility
L1 and L2 regularization:
L2 regularization tends to spread error among all the terms, while L1 is more binary/sparse, with many variables either being assigned a 1 or 0 in weighting. L1 corresponds to setting a Laplacean prior on the terms, while L2 corresponds to a Gaussian prior.
Type 1 error is a false positive
Type 2 error is a false negative
What is deep learning, and how does it contrast with other machine learning algorithms?
Deep learning is a subset of machine learning that is concerned with neural networks: how to use backpropagation and certain principles from neuroscience to more accurately model large sets of unlabelled or semi-structured data. In that sense, deep learning represents an unsupervised learning algorithm that learns representations of data through the use of neural nets.
Convolutional Neural Network:
a Deep Learning algorithm which can take in an input image, assign importance (learnable weights and biases) to various aspects/objects in the image and be able to differentiate one from the other.
A comprehensive guide to CNNs
What cross-validation technique would you use on a time series dataset?
K-folds with forward chaining. As it is inherently ordered by date and is biased towards the later dates
What is the difference between bagging and boosting?
https://quantdare.com/what-is-the-difference-between-bagging-and-boosting/
How would you build a data pipeline?
How would you implement a recommendation system?
Best Image ML competitions (video)
📖 NLP stands for Natural Language Processing, it pertains to the processing of large amounts of 'words' to extract information and insights.
Challenges in natural language processing frequently involve speech recognition, natural language understanding, and natural language generation.
Statistical: Part of Speech tagging, decision trees
Neural Networks: word embeddings, NER, bert
Lemmatization
The task of removing inflectional endings only and to return the base dictionary form of a word which is also known as a lemma. Lemmatization is another technique for reducing words to their normalized form. But in this case, the transformation actually uses a dictionary to map words to their actual form
Morphological segmentation
Separate words into individual morphemes and identify the class of the morphemes.
Part-of-speech tagging
Given a sentence, determine the part of speech (POS) for each word. Many words, especially common ones, can serve as multiple parts of speech. For example, "book" can be a noun ("the book on the table") or verb ("to book a flight"); "set" can be a noun, verb or adjective; and "out" can be any of at least five different parts of speech.
Stemming
The process of reducing inflected (or sometimes derived) words to a base form (e.g., "close" will be the root for "closed", "closing", "close", "closer" etc.). Stemming yields similar results as lemmatization, but does so on grounds of rules, not a dictionary.
Named entity recognition (NER)
Given a stream of text, determine which items in the text map to proper names, such as people or places, and what the type of each such name is (e.g. person, location, organization). Although capitalization can aid in recognizing named entities in languages such as English, this information cannot aid in determining the type of named entity, and in any case, is often inaccurate or insufficient. For example, the first letter of a sentence is also capitalized, and named entities often span several words, only some of which are capitalized. Furthermore, many other languages in non-Western scripts (e.g. Chinese or Arabic) do not have any capitalization at all, and even languages with capitalization may not consistently use it to distinguish names. For example, German capitalizes all nouns, regardless of whether they are names, and French and Spanish do not capitalize names that serve as adjectives.
Sentiment analysis (see also Multimodal sentiment analysis)
Extract subjective information usually from a set of documents, often using online reviews to determine "polarity" about specific objects. It is especially useful for identifying trends of public opinion in social media, for marketing.
BERT: https://www.kaggle.com/mdfahimreshm/bert-in-depth-understanding
===========================================================

- add spark and kafka and hadoop section
- add Go and Rust
- add messaging services section ie redis, redux, rabbitmq