Development
#summary DiVA omics main implementation challenges
A browser-based Distributed Interactive Visual Analysis System (DiVA) has to analyse large scale omics data while providing interactive visualization of the generated results on the client-side (which is resource limited).
In DiVA we can classify the main system functions into two main categories: (a) computations required for different analysis processes (profile plot, PCA, ranking analysis, and hierarchical clustering analysis) and (b) computations required to maintain the result visualization and coordinate the interactivity between the different visualization components.
The main challenges addressed by DiVA are related to category (b). Therefore the main challenge we are concerned with is how to distribute the data and workload across the different layers of the system to achieve both goals. Offloading the entire workload and data information to the server-side increases the network traffic which is likely to cause a big performance hit. On the other hand, reducing the networking calls will increase the load on the limited client.
The goal was to find the balance between increasing network calls and the workload on the client-side to optimize and maintain efficient interactive visual analysis system for large scale omics data.
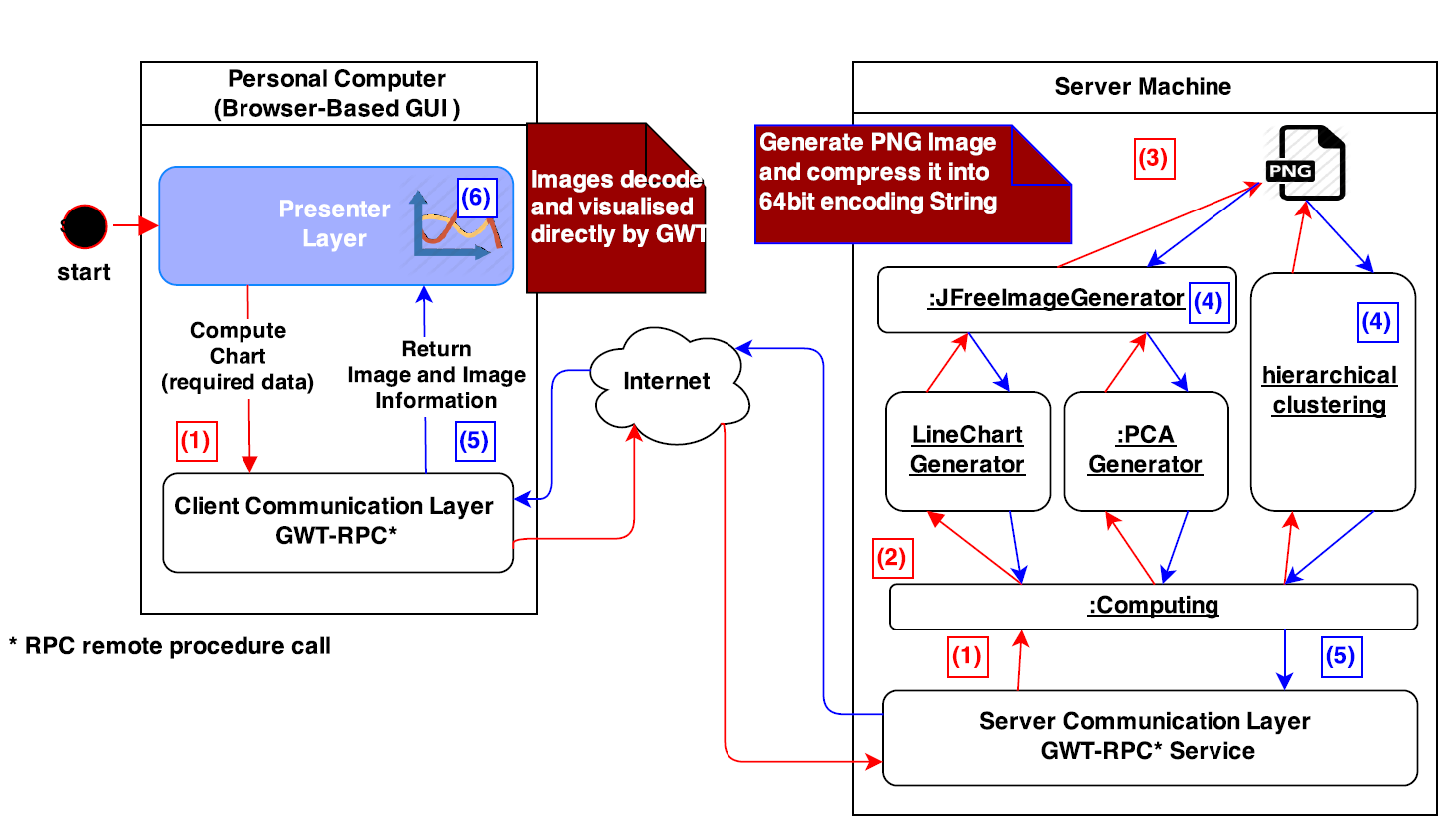
The figure show that the rendering process starts from the presenter layer (visualization component) where the client sends to the server the required information for rendering the graphs (selected data indexes in the case of PCA and Profile plot, and hierarchical clustering).
The server starts generating the chart images, compresses them into Base64 string and sends them back to the client combined with the information required for interactivity.
The process can be summarized in the following steps:
- The client sends request to render chart.
- The server processes the request.
- The server generates chart image.
- The server converts the images into Based64 strings.
- The server sends the images and information back to the client.
- The client visualize the image.
Using this technique boosts the performance of the client-side and reduces the effect of the data size to a minimum, where the results are represented on the client-side as a grid of pixels in an image. The high speed of GWT RPC communication plays a key role here by organizing the client-server connections and reducing the time required for client-server data transfer time.
Two additional features make the implementation of these components simpler and improve the system performance. First, is the auto image decoding for Base64 string supported in GWT. The images are transferred between client and server as strings and directly visualized on the client-side. Second, is the mouse event handlers supported by GWT for images. This feature provides an easy way to handle user selections on the images by calculating the selection coordinates and converting it into indexes.
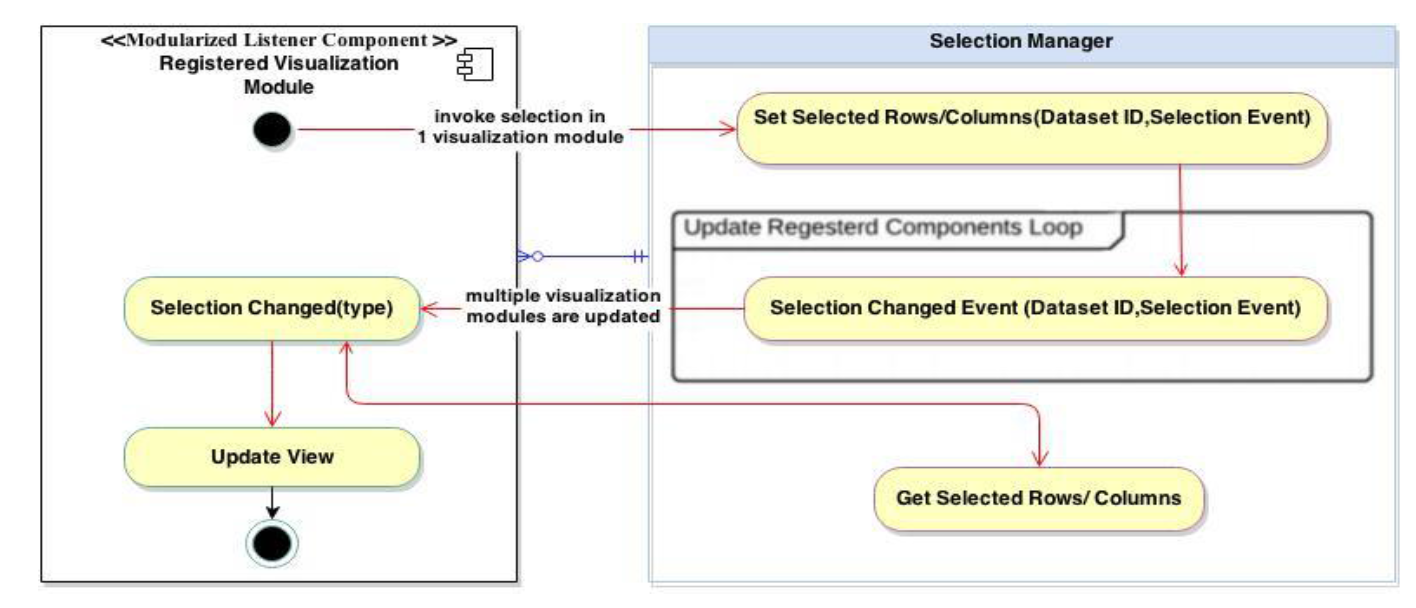
Selection-Manager is the component responsible for coordinating the user's selection notifications and sharing the selected data indexes between the different visualization modules. The component consists of two main Java classes; SelectionManager and ModularizedListener.
The ModularizedListener class is an abstraction class which contains the required functions and attributes for registering the visualization module component into the Selection-Manager. All visualization components inherit this class and implement the updating selection methods to be eligible for Selection-Manager registration and to allow the Selection-Manager to perform the required updates.
The modularised listener is the class responsible for unified the selection update process between different visualization components. The following activity diagram explains the central manager principle.