- Get only categorical, numerical
df.describe(include=[np.object]) # string
df.describe(include=[np.number]) # numeric
-
Logical indexing (in-place modif)
credit = credit[credit['Age'] > 0] -
Enumerate
animals = ["cat", "bird", "dog"]
... This unpacks a tuple.
print(i, element)
- Does not unpack the tuple.*
print(x, "UNPACKED =", x[0], x[1]]
Output
1 bird
2 dog
(0, 'cat') UNPACKED = 0 cat
(1, 'bird') UNPACKED = 1 bird
(2, 'dog') UNPACKED = 2 dog
- loc
max_speed shield
viper 4 5
sidewinder 7
>>> unique_index = pd.Index(list('abc'))
>>> unique_index.get_loc('b')
spambase = pd.read_csv(data_path, delimiter = ',')
-
extract input features
x = spambase_binary -
test outcome
y = pd.Series(y_test["is_spam"]) -
feed the Multionomial NB classifier
mnb.fit(x,y);
mnb.predict(X_test)
df = pd.DataFrame(data=spambase)
- One-dimensional ndarray with axis labels (including time series).
s = pd.Series(data, index=index)
Convert categorical variable into dummy/indicator variables
pd.get_dummies(s)
https://www.youtube.com/user/mathematicalmonk
https://www.coursera.org/specializations/mathematics-machine-learning
- MultinomialNB - naive Bayes algorithm for multinomially distributed data
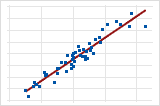
When both variables increase or decrease concurrently and at a constant rate, a positive linear relationship exists. The points in Plot 1 follow the line closely, suggesting that the relationship between the variables is strong.

When one variable increases while the other variable decreases, a negative linear relationship exists. The points in Plot 2 follow the line closely, suggesting that the relationship between the variables is strong.

The data points in Plot 3 appear to be randomly distributed. They do not fall close to the line indicating a very weak relationship if one exists.
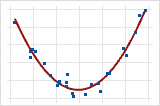
If a relationship between two variables is not linear, the rate of increase or decrease can change as one variable changes, causing a "curved pattern" in the data. This curved trend might be better modeled by a nonlinear function, such as a quadratic or cubic function, or be transformed to make it linear. Plot 4 shows a strong relationship between two variables.
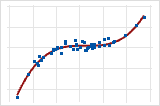
In a monotonic relationship, the variables tend to move in the same relative direction, but not necessarily at a constant rate. In a linear relationship, the variables move in the same direction at a constant rate. Plot 5 shows both variables increasing concurrently, but not at the same rate. This relationship is monotonic, but not linear.
Good function explanation: https://www.coursera.org/lecture/machine-learning/decision-boundary-WuL1H
coef_
The weight/coefficient matrix of a generalised linear model predictor, of shape (n_features,) for binary classification and single-output regression, (n_classes, n_features) for multiclass classification and (n_targets, n_features) for multi-output regression. Note this does not include the intercept (or bias) term, which is stored in intercept_.
A regression coefficient describes the size and direction of the relationship between a predictor and the response variable. Coefficients are the numbers by which the values of the term are multiplied in a regression equation.
Each of these correspond formally to a test of the null hypothesis that the coefficient in question is zero, while all the others are not (also known as the Wald test).
null hypothesis: null hypothesis that the coefficient is equal to zero (no effect)
I'm assuming that M[i,j] stands for Element of real class i was classified as j. If its the other way around you are going to need to transpose everything I say. I'm also going to use the following matrix for concrete examples:
1 2 3
4 5 6
7 8 9
There are essentially two things you can do:
Finding how each class has been classified
The first thing you can ask is what percentage of elements of real class i here classified as each class. To do so, we take a row fixing the i and divide each element by the sum of the elements in the row. In our example, objects from class 2 are classified as class 1 4 times, are classified correctly as class 2 5 times and are classified as class 3 6 times. To find the percentages we just divide everything by the sum 4 + 5 + 6 = 15
4/15 of the class 2 objects are classified as class 1
5/15 of the class 2 objects are classified as class 2
6/15 of the class 2 objects are classified as class 3
Finding what classes are responsible for each classification The second thing you can do is to look at each result from your classifier and ask how many of those results originate from each real class. Its going to be similar to the other case but with columns instead of rows. In our example, our classifier returns "1" 1 time when the original class is 1, 4 times when the original class is 2 and 7 times when the original class is 3. To find the percentages we divide by the sum 1 + 4 + 7 = 12
1/12 of the objects classified as class 1 were from class 1
4/12 of the objects classified as class 1 were from class 2
7/12 of the objects classified as class 1 were from class 3
-- Of course, both the methods I gave only apply to single row column at a time and I'm not sure if it would be a good idea to actually modify your confusion matrix in this form. However, this should give the percentages you are looking for.
- https://www.datacamp.com/community/tutorials/understanding-logistic-regression-python
- Interpretation: https://blog.minitab.com/blog/adventures-in-statistics-2/how-to-interpret-regression-analysis-results-p-values-and-coefficients
- https://ml-cheatsheet.readthedocs.io/en/latest/logistic_regression.html