
PaddleOCR performs the Optical Character Recognition (OCR) function from a video, an image, or a scanned document. It is mainly composed of three parts: DB text detection, detection frame correction and SVTR text recognition. For more details, refer to the PaddleOCR introduction.
This notebook demonstrates live PaddleOCR inference with OpenVINO, using the "Chinese and English ultra-lightweight PP-OCRv3 model(16.2M)" from PaddleOCR GitHub or PaddleOCR Gitee, which includes upgraded text detector and recognizer to improve accuracy compared to its previous version, PP-OCRv2. Both text detection and recognition results are visualized in a window, and text recognition results include both recognized text and its corresponding confidence level. The notebook shows how to create the following pipeline:
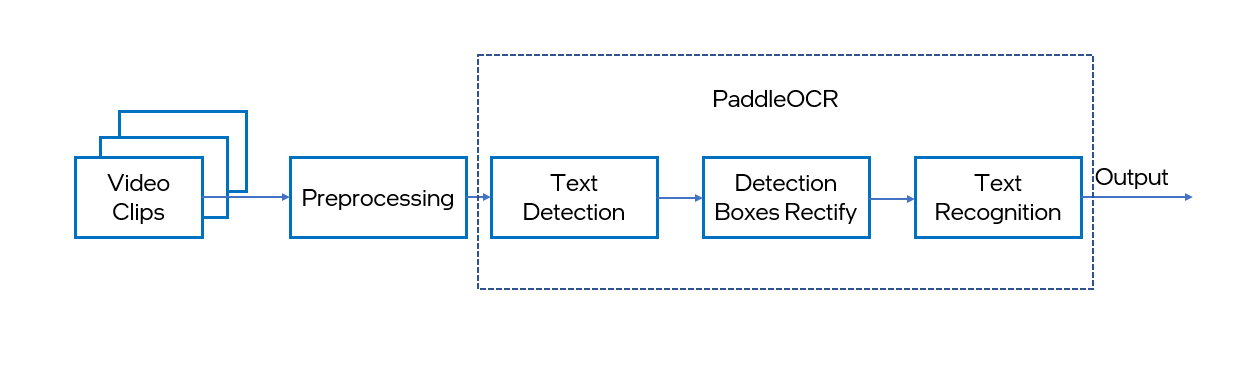
Final part of this notebook shows live inference results from a webcam. Additionally, you can also upload a video file.
NOTE: To use the webcam, you must run this Jupyter notebook on a computer with a webcam. If you run on a server, the webcam will not work. However, you can still do inference on a video in the final step.
For more information about the other PaddleOCR pre-trained models, refer to the PaddleOCR GitHub or PaddleOCR Gitee.
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.
For details, please refer to Installation Guide.