| 版本对应关系 | MindFormers | MindPet | MindSpore | Python | 芯片 |
|---|---|---|---|---|---|
| 版本号 | dev | 1.0.0 | 2.0/1.10 | 3.7.5/3.9.0 | Ascend910A NPU/CPU |
- docker下载命令
docker pull swr.cn-central-221.ovaijisuan.com/mindformers/mindformers_dev_mindspore_2_0:mindformers_0.6.0dev_20230616_py39_37- 创建容器
# --device用于控制指定容器的运行NPU卡号和范围
# -v 用于映射容器外的目录
# --name 用于自定义容器名称
docker run -it -u root \
--ipc=host \
--network host \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /etc/localtime:/etc/localtime \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /var/log/npu/:/usr/slog \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
--name {请手动输入容器名称} \
swr.cn-central-221.ovaijisuan.com/mindformers/mindformers_dev_mindspore_2_0:mindformers_0.6.0dev_20230616_py39_37 \
/bin/bash详情请参考MindFormers AICC使用教程
我们在镜像仓库网 (hqcases.com)上发布了一些经过验证的标准镜像版本,可以通过几行简单的docker命令的形式,直接使用验证过的标准镜像拉起MindFormers套件的训练任务,而无需进行较为繁琐的自定义镜像并上传的步骤。
- 镜像列表
1. swr.cn-central-221.ovaijisuan.com/mindformers/mindformers_dev_mindspore_1_10_1:mindformers_0.6.0dev_20230615_py39
- 在一台准备好docker引擎的计算机上,root用户执行docker pull命令拉取该镜像
docker pull swr.cn-central-221.ovaijisuan.com/mindformers/mindformers_dev_mindspore_1_10_1:mindformers_0.6.0dev_20230615_py39此处给出了MindFormers套件中支持的任务名称和模型名称,用于高阶开发时的索引名
| 模型 | 任务(task name) | 模型(model name) |
|---|---|---|
| BERT | masked_language_modeling text_classification token_classification question_answering |
bert_base_uncased txtcls_bert_base_uncased txtcls_bert_base_uncased_mnli tokcls_bert_base_chinese tokcls_bert_base_chinese_cluener qa_bert_base_uncased qa_bert_base_chinese_uncased |
| T5 | translation | t5_small |
| GPT2 | text_generation | gpt2_small gpt2_13b gpt2_52b |
| PanGuAlpha | text_generation | pangualpha_2_6_b pangualpha_13b |
| GLM | text_generation | glm_6b glm_6b_lora |
| GLM2 | text_generation | glm2_6b |
| LLama | text_generation | llama_7b llama_13b llama_65b llama_7b_lora |
| Bloom | text_generation | bloom_560m bloom_7.1b bloom_65b bloom_176b |
| MAE | masked_image_modeling | mae_vit_base_p16 |
| VIT | image_classification | vit_base_p16 |
| Swin | image_classification | swin_base_p4w7 |
| CLIP | contrastive_language_image_pretrain zero_shot_image_classification |
clip_vit_b_32 clip_vit_b_16 clip_vit_l_14 clip_vit_l_14@336 |
核心关键模型能力一览表:
| 关键模型 | 并行模式 | 数据并行 | 优化器并行 | 模型并行 | 流水并行 | 多副本并行 | 预训练 | 微调 | 评估 | 推理 | 是否上库 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT | data_parallel\semi_auto_parallel | 是 | 是 | 是 | 是 | 是 | 是 | 全参微调 | PPL评估 | 推理 | 是 |
| PanGu | data_parallel\semi_auto_parallel | 是 | 是 | 是 | 是 | 是 | 是 | 全参微调 | PPL评估 | 推理 | 是 |
| Bloom | data_parallel\semi_auto_parallel | 是 | 是 | 是 | 是 | 是 | 是 | 全参微调 | 不支持 | 推理 | 是 |
| LLaMa | data_parallel\semi_auto_parallel | 是 | 是 | 是 | 是 | 是 | 是 | 全参微调,Lora微调 | PPL评估 | 推理 | 是 |
| GLM/GLM2 | data_parallel\semi_auto_parallel | 是 | 是 | 是 | 是 | 是 | 是 | 全参微调,Lora微调 | Blue/Rouge评估 | 推理 | 是 |
其余库上模型分布式支持情况一览表:
| 模型 | 并行模式 | 数据并行 | 优化器并行 | 模型并行 | 流水并行 | 多副本并行 | 是否上库 |
|---|---|---|---|---|---|---|---|
| MAE | data_parallel | 是 | 是 | 否 | 否 | 否 | 是 |
| T5 | data_parallel | 是 | 是 | 否 | 否 | 否 | 是 |
| Bert | data_parallel | 是 | 是 | 否 | 否 | 否 | 是 |
| Swin | data_parallel | 是 | 是 | 否 | 否 | 否 | 是 |
| VIT | data_parallel | 是 | 是 | 否 | 否 | 否 | 是 |
| CLIP | data_parallel | 是 | 是 | 否 | 否 | 否 | 是 |
MindFormers大模型套件提供了AutoClass类,包含AutoConfig、AutoModel、AutoTokenizer、AutoProcessor4个便捷高阶接口,方便用户调用套件中已封装的API接口。上述4类提供了相应领域模型的ModelConfig、Model、Tokenzier、Processor的实例化功能。
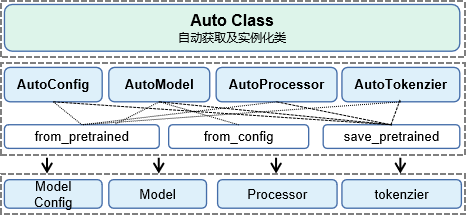
| AutoClass类 | from_pretrained属性(实例化功能) | from_config属性(实例化功能) | save_pretrained(保存配置功能) |
|---|---|---|---|
| AutoConfig | √ | × | √ |
| AutoModel | √ | √ | √ |
| AutoProcessor | √ | × | √ |
| AutoTokenizer | √ | × | √ |
使用AutoConfig和AutoModel自动实例化MindFormers中支持的模型配置或模型架构:
from mindformers import AutoConfig, AutoModel
gpt_config = AutoConfig.from_pretrained("gpt2")
gpt_model = AutoModel.from_pretrained("gpt2") # 自动加载预置权重到网络中使用已有模型配置或网络架构实例化相应的模型配置或网络架构实例:
from mindformers import GPT2LMHeadModel, GPT2Config
gpt_13b_config = GPT2Config.from_pretrained("gpt2_13b")
gpt_13b_model = GPT2LMHeadModel.from_pretrained("gpt2_13b") # 自动加载预置权重到网络中使用已有模型配置或模型架构进行二次开发:
from mindformers import GPT2LMHeadModel, GPT2Config
gpt_config = GPT2Config(hidden_size=768, num_layers=12)
gpt_model = GPT2LMHeadModel(gpt_config)使用AutoTokenizer自动获取文本分词器:
from mindformers import AutoTokenizer
gpt_tokenizer = AutoTokenizer.from_pretrained("gpt2")
gpt_tokenizer("hello!"){'input_ids': [50256, 31373, 0, 50256], 'token_type_ids': [0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1]}
使用已有Tokenizer函数对文本进行分词:
from mindformers import GPT2Tokenizer
gpt_tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
gpt_tokenizer("hello!"){'input_ids': [50256, 31373, 0, 50256], 'token_type_ids': [0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1]}
使用AutoProcessor自动获取模型数据预处理过程:
from mindformers import AutoProcessor
gpt_processor = AutoProcessor.from_pretrained("gpt2")
gpt_processor("hello!"){'text': Tensor(shape=[1, 128], dtype=Int32, value=
[[50256, 31373, 0 ... 50256, 50256, 50256]])}
使用已有模型数据预处理过程对相应数据做模型输入前的预处理:
from mindformers import GPT2Processor
gpt_processor = GPT2Processor.from_pretrained('gpt2')
gpt_processor("hello!"){'text': Tensor(shape=[1, 128], dtype=Int32, value=
[[50256, 31373, 0 ... 50256, 50256, 50256]])}
使用已有数据预处理过程进行二次开发:
from mindformers import GPT2Processor, GPT2Tokenizer
# 自定义 tokenizer
tok = GPT2Tokenizer.from_pretrained("gpt2")
gpt_processor = GPT2Processor(tokenizer=tok, max_length=256, return_tensors='ms')
gpt_processor("hello!"){'text': Tensor(shape=[1, 256], dtype=Int32, value=
[[50256, 31373, 0 ... 50256, 50256, 50256]])}
MindFormers大模型套件面向任务设计pipeline推理接口,旨在让用户可以便捷的体验不同AI领域的大模型在线推理服务,当前已集成10+任务的推理流程;
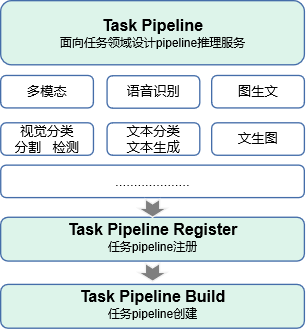
使用MindFormers预置任务和模型开发一个推理流:
from mindformers import pipeline
text_generation = pipeline(task='text_generation', model='gpt2', max_length=50)
text_generation("I love Beijing, because", top_k=3)[{'text_generation_text': ['I love Beijing, because of all its beautiful scenery and beautiful people," said the mayor of Beijing, who was visiting the capital for the first time since he took office.\n\n"The Chinese government is not interested in any of this," he added']}]
使用自定义的模型、tokenizer等进行任务推理:
from mindformers import pipeline
from mindformers import GPT2LMHeadModel, GPT2Config, GPT2Tokenizer
tok = GPT2Tokenizer.from_pretrained("gpt2")
gpt_model = GPT2LMHeadModel.from_pretrained("gpt2")
text_generation = pipeline(task='text_generation', model=gpt_model, tokenizer=tok, max_length=50)
text_generation("I love Beijing, because", top_k=3)[{'text_generation_text': ['I love Beijing, because of all its beautiful scenery and beautiful people," said the mayor of Beijing, who was visiting the capital for the first time since he took office.\n\n"The Chinese government is not interested in any of this," he added']}]
MindFormers大模型套件面向任务设计Trainer接口,旨在让用户可以快速使用我们预置任务和模型的训练、微调、评估、推理能力,当前已集成10+任务和10+模型的全流程开发能力;
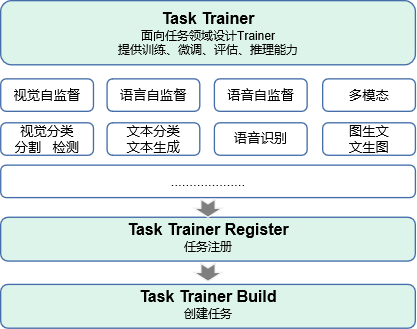
mindspore相关环境的初始化,MindFormers中提供了init_context标准接口帮助用户完成单卡或多卡并行环境的初始化:
init_context ContextConfig ParallelContextConfig
单卡初始化:
from mindformers import init_context, ContextConfig
def context_init():
"""init context for mindspore."""
context_config = ContextConfig(mode=0, device_target="Ascend", device_id=0)
rank_id, device_num = init_context(use_parallel=False, context_config=context_config)多卡数据并行模式初始化:
from mindformers import init_context, ContextConfig, ParallelContextConfig
def context_init():
"""init context for mindspore."""
context_config = ContextConfig(mode=0, device_target="Ascend", device_id=0)
parallel_config = ParallelContextConfig(parallel_mode='DATA_PARALLEL', gradients_mean=True,
enable_parallel_optimizer=False)
rank_id, device_num = init_context(use_parallel=True, context_config=context_config,
parallel_config=parallel_config)多卡半自动并行模式初始化:
from mindformers import init_context, ContextConfig, ParallelContextConfig
def context_init():
"""init context for mindspore."""
context_config = ContextConfig(mode=0, device_target="Ascend", device_id=0)
parallel_config = ParallelContextConfig(parallel_mode='SEMI_AUTO_PARALLEL', gradients_mean=False,
enable_parallel_optimizer=False, full_batch=True)
rank_id, device_num = init_context(use_parallel=True, context_config=context_config,
parallel_config=parallel_config)MindFormers套件对用户提供了TrainingArguments类,用于自定义大模型训练过程中的各类参数,支持参数详见:TrainingArguments
同时,MindFormers也提供了Trainer高阶接口,用于大模型任务的开发、训练、微调、评估、推理等流程;
使用TrainingArguments自定义大模型训练过程参数:
from mindformers import TrainingArguments
# 环境初始化,参考上述`init_context`章节实现
context_init()
# 训练超参数定义
training_args = TrainingArguments(num_train_epochs=3, batch_size=2, learning_rate=0.001, warmup_steps=1000,
sink_mode=True)使用Trainer接口创建内部预置任务:数据集按照官方教程准备GPT预训练数据集准备,自定义训练参数
from mindformers import Trainer, TrainingArguments
# 环境初始化,参考上述`init_context`章节实现
context_init()
# 训练超参数定义
training_args = TrainingArguments(num_train_epochs=3, batch_size=2, learning_rate=0.001, warmup_steps=1000,
sink_mode=True)
text_generation = Trainer(task='text_generation', model='gpt2', args=training_args, train_dataset='./train',
eval_dataset='./eval')使用Trainer接口创建内部预置任务:自定义数据集,模型,训练参数
from mindspore.dataset import GeneratorDataset
from mindformers import Trainer, TrainingArguments, AutoModel
def generator():
"""text dataset generator."""
seq_len = 1025
input_ids = np.random.randint(low=0, high=15, size=(seq_len,)).astype(np.int32)
for _ in range(512):
yield input_ids
# 环境初始化,参考上述`init_context`章节实现
context_init()
# 自定义训练超参数
training_args = TrainingArguments(num_train_epochs=3, batch_size=2, learning_rate=0.001, warmup_steps=1000,
sink_mode=True)
# 自定义模型
pangu_model = AutoModel.from_pretrained("pangualpha_2_6b")
# 自定义数据集
dataset = GeneratorDataset(generator, column_names=["input_ids"])
train_dataset = dataset.batch(batch_size=4)
eval_dataset = dataset.batch(batch_size=4)
# 定义文本生成任务,传入自定义模型、数据集、超参数
text_generation = Trainer(task='text_generation', model=pangu_model, args=training_args, train_dataset=train_dataset,
eval_dataset=eval_dataset)MindFormers的Trainer接口提供了并行的配置接口set_parallel_config和重计算配置接口set_recompute_config,其中set_parallel_config接口仅在半自动并行
或全自动并行模式下生效,同时需要模型本身已支持或已配置并行策略;
set_parallel_config set_recompute_config
使用Trainer高阶接口,自定义并行和重计算配置:
import numpy as np
from mindspore.dataset import GeneratorDataset
from mindformers import Trainer, TrainingArguments
from mindformers import PanguAlphaHeadModel, PanguAlphaConfig
def generator():
"""text dataset generator."""
seq_len = 1025
input_ids = np.random.randint(low=0, high=15, size=(seq_len,)).astype(np.int32)
for _ in range(512):
yield input_ids
# 环境初始化,参考上述`init_context`章节实现
context_init()
# 自定义训练超参数
training_args = TrainingArguments(num_train_epochs=3, batch_size=2, learning_rate=0.001, warmup_steps=1000,
sink_mode=True)
# 自定义模型
pangu_config = PanguAlphaConfig(hidden_size=768, ffn_hidden_size=768 * 4, num_layers=12, num_heads=12,
checkpoint_name_or_path='')
pangu_model = PanguAlphaHeadModel(pangu_config)
# 自定义数据集
dataset = GeneratorDataset(generator, column_names=["input_ids"])
train_dataset = dataset.batch(batch_size=4)
eval_dataset = dataset.batch(batch_size=4)
# 定义文本生成任务,传入自定义模型、数据集、超参数
text_generation = Trainer(task='text_generation', model=pangu_model, args=training_args, train_dataset=train_dataset,
eval_dataset=eval_dataset)
# 设定并行策略,比如2机16卡,设定数据并行4 模型并行2 流水并行2 微批次大小为2 打开优化器并行
text_generation.set_parallel_config(data_parallel=4, model_parallel=2, pipeline_stage=2, micro_batch_num=2)
# 设置重计算配置,打开重计算
text_generation.set_recompute_config(recompute=True)MindFormers套件的Trainer高阶接口提供了train、finetune、evaluate、predict
4个关键属性函数,帮助用户快速拉起任务的训练、微调、评估、推理流程:Trainer.train Trainer.finetune Trainer.evaluate Trainer.predict
使用Trainer.train Trainer.finetune Trainer.evaluate Trainer.predict 拉起任务的训练、微调、评估、推理流程,以下为使用Trainer
高阶接口进行全流程开发的使用样例(多卡分布式并行),命名为task.py:
import argparse
from mindformers import Trainer, TrainingArguments
from mindformers import init_context, ContextConfig, ParallelContextConfig
def context_init(use_parallel=False, optimizer_parallel=False):
"""init context for mindspore."""
context_config = ContextConfig(mode=0, device_target="Ascend", device_id=0)
parallel_config = None
if use_parallel:
parallel_config = ParallelContextConfig(parallel_mode='SEMI_AUTO_PARALLEL',
gradients_mean=False,
enable_parallel_optimizer=optimizer_parallel,
full_batch=True)
rank_id, device_num = init_context(use_parallel=use_parallel,
context_config=context_config,
parallel_config=parallel_config)
def main(use_parallel=False,
run_mode='train',
task='text_generation',
model_type='gpt2',
pet_method='',
train_dataset='./train',
eval_dataset='./eval',
predict_data='hello!',
dp=1, mp=1, pp=1, micro_size=1, op=False):
# 环境初始化
context_init(use_parallel, op)
# 训练超参数定义
training_args = TrainingArguments(num_train_epochs=1, batch_size=2, learning_rate=0.001, warmup_steps=100,
sink_mode=True, sink_size=2)
# 定义任务,预先准备好相应数据集
task = Trainer(task=task,
model=model_type,
pet_method=pet_method,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset)
task.set_parallel_config(data_parallel=dp,
model_parallel=mp,
pipeline_stage=pp,
micro_batch_num=micro_size)
if run_mode == 'train':
task.train()
elif run_mode == 'finetune':
task.finetune()
elif run_mode == 'eval':
task.evaluate()
elif run_mode == 'predict':
result = task.predict(input_data=predict_data)
print(result)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--run_mode', default='train', required=True, help='set run mode for model.')
parser.add_argument('--use_parallel', default=False, help='open parallel for model.')
parser.add_argument('--task', default='text_generation', required=True, help='set task type.')
parser.add_argument('--model_type', default='gpt2', required=True, help='set model type.')
parser.add_argument('--train_dataset', default=None, help='set train dataset.')
parser.add_argument('--eval_dataset', default=None, help='set eval dataset.')
parser.add_argument('--pet_method', default='', help="set finetune method, now support type: ['', 'lora']")
parser.add_argument('--data_parallel', default=1, type=int, help='set data parallel number. Default: None')
parser.add_argument('--model_parallel', default=1, type=int, help='set model parallel number. Default: None')
parser.add_argument('--pipeline_parallel', default=1, type=int, help='set pipeline parallel number. Default: None')
parser.add_argument('--micro_size', default=1, type=int, help='set micro batch number. Default: None')
parser.add_argument('--optimizer_parallel', default=False, type=bool,
help='whether use optimizer parallel. Default: None')
args = parser.parse_args()
main(run_mode=args.run_mode,
task=args.task,
use_parallel=args.use_parallel,
model_type=args.model_type,
pet_method=args.pet_method,
train_dataset=args.train_dataset,
eval_dataset=args.eval_dataset,
dp=args.data_parallel,
mp=args.model_parallel,
pp=args.pipeline_parallel,
micro_size=args.micro_size,
op=args.optimizer_parallel)- 单卡使用样例:
# 训练
python task.py --task text_generation --model_type gpt2 --train_dataset ./train --run_mode train
# 评估
python task.py --task text_generation --model_type gpt2 --eval_dataset ./eval --run_mode eval
# 微调,支持
python task.py --task text_generation --model_type gpt2 --train_dataset ./finetune --pet_method lora --run_mode finetune
# 推理
python task.py --task text_generation --model_type gpt2 --predict_data 'hello!' --run_mode predict-
多卡分布式使用样例:
-
单机多卡标准启动脚本:
run_distribute_single_node.sh#!/bin/bash # Copyright 2023 Huawei Technologies Co., Ltd # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ============================================================================ if [ $# != 4 ] then echo "Usage Help: bash run_distribute_single_node.sh [EXECUTE_ORDER] [RANK_TABLE_PATH] [DEVICE_RANGE] [RANK_SIZE] For Multiple Devices In Single Machine" exit 1 fi check_real_path(){ if [ "${1:0:1}" == "/" ]; then echo "$1" else echo "$(realpath -m $PWD/$1)" fi } EXECUTE_ORDER=$1 RANK_TABLE_PATH=$(check_real_path $2) DEVICE_RANGE=$3 DEVICE_RANGE_LEN=${#DEVICE_RANGE} DEVICE_RANGE=${DEVICE_RANGE:1:DEVICE_RANGE_LEN-2} PREFIX=${DEVICE_RANGE%%","*} INDEX=${#PREFIX} START_DEVICE=${DEVICE_RANGE:0:INDEX} END_DEVICE=${DEVICE_RANGE:INDEX+1:DEVICE_RANGE_LEN-INDEX} if [ ! -f $RANK_TABLE_PATH ] then echo "error: RANK_TABLE_FILE=$RANK_TABLE_PATH is not a file" exit 1 fi if [[ ! $START_DEVICE =~ ^[0-9]+$ ]]; then echo "error: start_device=$START_DEVICE is not a number" exit 1 fi if [[ ! $END_DEVICE =~ ^[0-9]+$ ]]; then echo "error: end_device=$END_DEVICE is not a number" exit 1 fi ulimit -u unlimited export RANK_SIZE=$4 export RANK_TABLE_FILE=$RANK_TABLE_PATH shopt -s extglob for((i=${START_DEVICE}; i<${END_DEVICE}; i++)) do export DEVICE_ID=${i} export RANK_ID=$((i-START_DEVICE)) mkdir -p ./output/log/rank_$RANK_ID echo "start training for rank $RANK_ID, device $DEVICE_ID" $EXECUTE_ORDER &> ./output/log/rank_$RANK_ID/mindformer.log & done shopt -u extglob
-
多机多卡标准启动脚本:
run_distribute_multi_node.sh#!/bin/bash # Copyright 2023 Huawei Technologies Co., Ltd # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ============================================================================ if [ $# != 4 ] then echo "Usage Help: bash run_distribute_multi_node.sh [EXECUTE_ORDER] [RANK_TABLE_FILE] [DEVICE_RANGE] [RANK_SIZE]" exit 1 fi check_real_path(){ if [ "${1:0:1}" == "/" ]; then echo "$1" else echo "$(realpath -m $PWD/$1)" fi } EXECUTE_ORDER=$1 RANK_TABLE_PATH=$(check_real_path $2) DEVICE_RANGE=$3 DEVICE_RANGE_LEN=${#DEVICE_RANGE} DEVICE_RANGE=${DEVICE_RANGE:1:DEVICE_RANGE_LEN-2} PREFIX=${DEVICE_RANGE%%","*} INDEX=${#PREFIX} START_DEVICE=${DEVICE_RANGE:0:INDEX} END_DEVICE=${DEVICE_RANGE:INDEX+1:DEVICE_RANGE_LEN-INDEX} if [ ! -f $RANK_TABLE_PATH ] then echo "error: RANK_TABLE_FILE=$RANK_TABLE_PATH is not a file" exit 1 fi if [[ ! $START_DEVICE =~ ^[0-9]+$ ]]; then echo "error: start_device=$START_DEVICE is not a number" exit 1 fi if [[ ! $END_DEVICE =~ ^[0-9]+$ ]]; then echo "error: end_device=$END_DEVICE is not a number" exit 1 fi ulimit -u unlimited export RANK_SIZE=$4 export RANK_TABLE_FILE=$RANK_TABLE_PATH shopt -s extglob for((i=${START_DEVICE}; i<${END_DEVICE}; i++)) do export RANK_ID=${i} export DEVICE_ID=$((i-START_DEVICE)) echo "start training for rank $RANK_ID, device $DEVICE_ID" mkdir -p ./output/log/rank_$RANK_ID $EXECUTE_ORDER &> ./output/log/rank_$RANK_ID/mindformer.log & done shopt -u extglob
-
分布式并行执行
task.py样例:需提前生成RANK_TABLE_FILE,同时task.py中默认使用半自动并行模式。注意单机时使用{single},多机时使用{multi}
# 分布式训练 bash run_distribute_{single/multi}_node.sh "python task.py --task text_generation --model_type gpt2 --train_dataset ./train --run_mode train --use_parallel True --data_parallel 1 --model_parallel 2 --pipeline_parallel 2 --micro_size 2" hccl_4p_0123_192.168.89.35.json [0,4] 4 # 分布式评估 bash run_distribute_{single/multi}_node.sh "python task.py --task text_generation --model_type gpt2 --eval_dataset ./eval --run_mode eval --use_parallel True --data_parallel 1 --model_parallel 2 --pipeline_parallel 2 --micro_size 2" hccl_4p_0123_192.168.89.35.json [0,4] 4 # 分布式微调 bash run_distribute_{single/multi}_node.sh "python task.py --task text_generation --model_type gpt2 --train_dataset ./train --run_mode finetune --pet_method lora --use_parallel True --data_parallel 1 --model_parallel 2 --pipeline_parallel 2 --micro_size 2" hccl_4p_0123_192.168.89.35.json [0,4] 4 # 分布式推理(不支持流水并行,试用特性) bash run_distribute_{single/multi}_node.sh "python task.py --task text_generation --model_type gpt2 --predict_data 'hello!' --run_mode predict --pet_method lora --use_parallel True --data_parallel 1 --model_parallel 2" hccl_4p_0123_192.168.89.35.json [0,4] 4
-
MindPet(Pet:Parameter-Efficient Tuning)是属于Mindspore领域的微调算法套件。随着计算算力不断增加,大模型无限的潜力也被挖掘出来。但随之在应用和训练上带来了巨大的花销,导致商业落地困难。因此,出现一种新的参数高效(parameter-efficient)算法,与标准的全参数微调相比,这些算法仅需要微调小部分参数,可以大大降低计算和存储成本,同时可媲美全参微调的性能。
| 模型 | 微调算法 | 运行模式 |
|---|---|---|
| GPT | Lora | finetune、eval、predict |
| LLama | Lora | finetune、eval、predict |
| GLM | Lora | finetune、eval、predict |
| GLM2 | Lora | finetune、eval、predict |
Mindformers大模型套件提供了text generator方法,旨在让用户能够便捷地使用生成类语言模型进行文本生成任务,包括但不限于解答问题、填充不完整文本或翻译源语言到目标语言等。
当前该方法支持Minformers大模型套件中7个生成类语言模型
| model | 模型文档链接 | 增量推理 | 流式推理 |
|---|---|---|---|
| bloom | link | √ | √ |
| GLM | link | √ | √ |
| GLM2 | link | √ | √ |
| GPT | link | × | √ |
| llama | link | √ | √ |
| pangu-alpha | link | × | √ |
| T5 | link | × | √ |
Mindformers大模型套件的text generator方法支持增量推理逻辑,该逻辑旨在加快用户在调用text generator方法进行文本生成时的文本生成速度。
通过实例化的模型调用:
from mindspore import set_context
from mindformers import GLMChatModel, ChatGLMTokenizer, GLMConfig
set_context(mode=0)
# use_past设置成True时为增量推理,反之为自回归推理
glm_config = GLMConfig(use_past=True, checkpoint_name_or_path="glm_6b")
glm_model = GLMChatModel(glm_config)
tokenizer = ChatGLMTokenizer.from_pretrained("glm_6b")
words = "中国的首都是哪个城市?"
words = tokenizer(words)['input_ids']
output = glm_model.generate(words, max_length=20, top_k=1)
output = tokenizer.decode(output[0], skip_special_tokens=True)
print(output)
# 中国的首都是哪个城市? 中国的首都是北京。Mindformers大模型套件提供Streamer类,旨在用户在调用text generator方法进行文本生成时能够实时看到生成的每一个词,而不必等待所有结果均生成结束。
实例化streamer并向text generator方法传入该实例:
from mindformers import GPT2LMHeadModel, GPT2Tokenizer, TextStreamer
tok = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
inputs = tok(["An increasing sequence: one,"], return_tensors=None, add_special_tokens=False)
streamer = TextStreamer(tok)
_ = model.generate(inputs["input_ids"], streamer=streamer, max_length=20, top_k=1)
# 'An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,'说明: 由于MindSpore版本问题,分布式推理仅支持MindSpore 2.0及以上版本,且暂不支持流水并行推理模式。
大模型的训练效果需要评测任务来作为衡量标准,而当前大模型的训练耗时长,等到训练整体结束后再进行评测任务的时间与算力成本过高
本功能提供了一套在训练过程中进行评估的流程方法,以动态观察模型的评估结果,具有以下特性:
- 能够在训练过程中执行评估流程,并在日志中打印相关的评估结果信息;
- 具有功能开关,根据开关状态决定是否启用边训练边评估功能;
- 具备调用间隔控制项,根据该控制项决定调用边训练边评估功能的时间间隔;
- 支持多种模型,只要模型能够调用Model.eval()完成评估,都可以复用该项功能;无法通过Model.eval()完成评估的模型则需要额外编码适配,暂不支持;
| 模型 | 评估指标 | 可用Model.eval完成评估 | 是否支持 | 数据并行模式 | 半自动并行模式 |
|---|---|---|---|---|---|
| bert | - | - | - | - | - |
| bloom | - | - | - | - | - |
| clip | - | - | - | - | - |
| filip | - | - | - | - | - |
| glm | Rouge,Bleu | 否 | 否 | × | × |
| glm2 | Rouge,Bleu | 否 | 否 | × | × |
| gpt2 | PPL | 是 | 是 | √ | √ |
| llama | PPL | 是 | 是 | √ | √(7b 至少8卡) |
| MAE | 暂缺 | - | - | - | - |
| pangu alpha | PPL | 是 | 是 | √ | √ |
| qa-bert | f1, precision, recall | 是 | 是 | √ | × |
| swin | Accuracy | 是 | 是 | √ | × |
| t5 | 暂缺 | - | - | - | - |
| tokcls-bert | f1, precision, recall | 是 | 是 | √ | × |
| txtcls-bert | Accuracy | 是 | 是 | √ | × |
| vit | Accuracy | 是 | 是 | √ | × |
说明:边训练边评估功能需模型已支持评估,并且该评估指标可以通过Model.eval()完成
- run_mindformer启用边训练边评估
描述:通过run_mindformers脚本参数,启用边训练边评估功能
测试方式:--do_eval开关启用边训练边评估功能,--eval_dataset_dir指定评估数据集
python run_mindformer.py \
--config configs/gpt2/run_gpt2.yaml \
--run_mode train \
--train_dataset_dir /your_path/wikitext-2-train-mindrecord \
--eval_dataset_dir /your_path/wikitext-2-eval-mindrecord \
--do_eval True- trainer启用边训练边评估
描述:通过Trainer高阶接口入参,启用边训练边评估功能 测试方式:执行以下python脚本,其中数据集路径替换为实际路径
def test_trainer_do_eval():
from mindformers.trainer import Trainer
# 初始化预训练任务
trainer = Trainer(task='text_generation', model='gpt2',
train_dataset="/your_path/wikitext-2-train-mindrecord",
eval_dataset="/your_path/wikitext-2-eval-mindrecord")
# 开启训练,并打开do_eval开关
trainer.train(do_eval=True)
if __name__ == "__main__":
test_trainer_do_eval()- 配置评估间隔时间
描述:更改评估间隔时间,以控制执行评估的频率
测试方式:更改配置项,将 configs/gpt2/run_gpt2.yaml 文件中的 eval_epoch_interval 项修改为其他数值
执行run_mindformer.py启用边训练边评估中的启动脚本
do_eval: False
eval_step_interval: -1 # num of step intervals between each eval, -1 means no step end eval.
# 修改此项eval_epoch_interval数值:
eval_epoch_interval: 50 # num of epoch intervals between each eval, 1 means eval on every epoch end.该特性适用于:1. 权重过大,单卡无法加载;2. 权重为切分权重且与目标网络和运行卡数不匹配;
此时可利用本特性进行权重的切分和转换,以适配目标网络运行;
使用场景:1. 分布式恢复训练(恢复时卡数或者并行策略发生改变);2. 评估/推理场景(权重需要进一步切分或者合并)
- step1(默认已有待切分权重相对应的策略文件,若没有,也可参考以下方法生成)
在config中配置only_save_strategy: True,正常启动分布式训练/评估/推理,生成目标卡数的分布式策略文件后将会退出。生成的分布式策略文件保存在output/strategy目录下。
only_save_strategy: True- step2
在物理机上,运行如下脚本完成权重切分转换
python mindformers/tools/transform_ckpt.py --src_ckpt_strategy SRC_CKPT_STRATEGY --dst_ckpt_strategy DST_CKPT_STRATEGY --src_ckpt_dir SRC_CKPT_DIR --dst_ckpt_dir DST_CKPT_DIR
# 参数说明
# src_ckpt_strategy:待转权重的分布式策略文件路径。
若为None,表示待转权重为完整权重;
若为切分策略文件,表示原始的权重对应的策略文件;
若为文件夹,表示需要合并文件夹内策略文件(仅在流水并行生成的策略文件时需要),合并后的策略文件保存在`SRC_CKPT_STRATEGY/merged_ckpt_strategy.ckpt`路径下;
# dst_ckpt_strategy:目标权重的分布式策略文件路径。即step1中生成的分布式策略文件路径。
若为None,表示将待转权重合并为完整权重;
若为切分策略文件,表示目标卡数对应的策略文件
若为文件夹,表示需要合并文件夹内策略文件(仅在流水并行生成的策略文件时需要),合并后的策略文件保存在`DST_CKPT_STRATEGY/merged_ckpt_strategy.ckpt`路径下;
# src_ckpt_dir: 待转权重路径,须按照`SRC_CKPT_DIR/rank_{i}/checkpoint_{i}.ckpt`存放,比如单一权重存放格式为`SRC_CKPT_DIR/rank_0/checkpoint_0.ckpt`。
# dst_ckpt_dir:目标权重保存路径,为自定义空文件夹路径,转换后模型以`DST_CKPT_DIR/rank_{i}/xxx.ckpt`存放。- step3
将config的配置文件中load_checkpoint关键字指定为转换的目标权重保存路径,若转换后仍为切分权重,传入转换后的权重文件夹路径即可;若转换后为完整权重,传入权重文件路径即可正常启动训练。
load_checkpoint: "{转换后权重文件夹/文件路径}"使用TrainingArguments类打开only_save_strategy字段,其余步骤可参考方案1
基本步骤和物理机相同,需要先通过NoteBook或者训练作业来收集原始或目标网络的并行策略文件;
注意:mindformers/tools/transform_ckpt.py转换接口仅在MindSpore2.0环境下使用,可以在NoteBook中安装MindSpore2.0 CPU版本,进行离线转换;
-
step1
在
config或者训练作业中配置超参only_save_strategy=True,拉起训练作业,仅生成分布式策略文件。生成的分布式策略文件保存在
remote_save_url/strategy目录下。(remote_save_url表示obs存储路径)- 方式1:config中修改only_save_strategy参数
only_save_strategy: True
- 方式2:训练作业界面中增加
only_save_strategy超参
-
step2

启动NoteBook任务,运行如下脚本完成权重切分转换(注意在MindSpore 2.0版本下)
python mindformers/tools/transform_ckpt.py --src_ckpt_strategy SRC_CKPT_STRATEGY --dst_ckpt_strategy DST_CKPT_STRATEGY --src_ckpt_dir SRC_CKPT_DIR --dst_ckpt_dir DST_CKPT_DIR
# 参数说明
# src_ckpt_strategy:待转权重的分布式策略文件路径。
若为None,表示待转权重为完整权重;
若为切分策略文件,表示原始的权重对应的策略文件;
若为文件夹,表示需要合并文件夹内策略文件(仅在流水并行生成的策略文件时需要),合并后的策略文件保存在`SRC_CKPT_STRATEGY/merged_ckpt_strategy.ckpt`路径下;
# dst_ckpt_strategy:目标权重的分布式策略文件路径。即step1中生成的分布式策略文件路径。
若为None,表示将待转权重合并为完整权重;
若为切分策略文件,表示目标卡数对应的策略文件
若为文件夹,表示需要合并文件夹内策略文件(仅在流水并行生成的策略文件时需要),合并后的策略文件保存在`DST_CKPT_STRATEGY/merged_ckpt_strategy.ckpt`路径下;
# src_ckpt_dir: 待转权重路径,须按照`SRC_CKPT_DIR/rank_{i}/checkpoint_{i}.ckpt`存放,比如单一权重存放格式为`SRC_CKPT_DIR/rank_0/checkpoint_0.ckpt`。
# dst_ckpt_dir:目标权重保存路径,为自定义空文件夹路径,转换后模型以`DST_CKPT_DIR/rank_{i}/xxx.ckpt`存放。- step3
将切分转换好的权重传到OBS(若仅在NoteBook上运行可不用传输到OBS上),将config的配置文件中load_checkpoint关键字指定为转换的目标权重保存路径,若转换后仍为切分权重,传入转换后的权重文件夹路径即可;若转换后为完整权重,传入权重文件路径即可正常启动训练。
load_checkpoint: "{转换后权重文件夹/文件路径}"